# Review :Main idea of word2vec
Start with random word vectors
Iterate through each word in the whole corpus
Try to predict surrounding words using word vectors :
**Learning 😗*Update vectors so they can predict actual surroundings words better
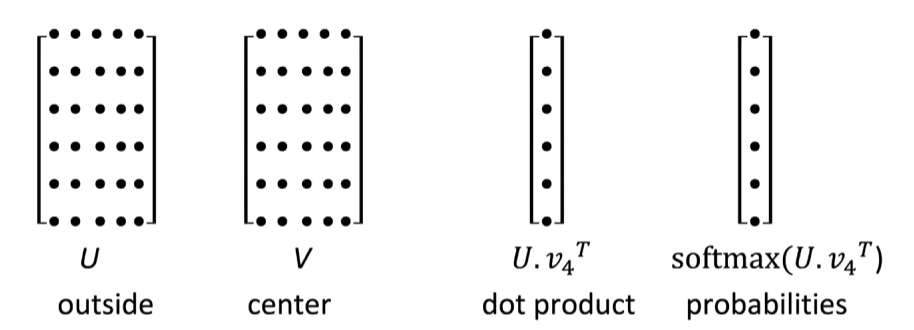
- Taking their dot product to get a probability to get a score of how likely a particular outside word is to occur with the center word.
- Then using the softmax transformation to convert those scores into probabilities.
- This model is what we call in NLP,a bag of words model,which don't actually pay any attention to word order or position. It doesn't matter if you're next to the center word or a bit further away on the left or right.The probability estimate would be the same.
- with this model we wanna to give reasonably high probabilities to the words that do occur in the context of the center word,at least if they do so at all often.
- Obviously lots of different words can occur,which means we more likely to talk about probabilities like 0.01 and numbers like that.
- Word2vec maximizes objective function by putting similar words nearby in space
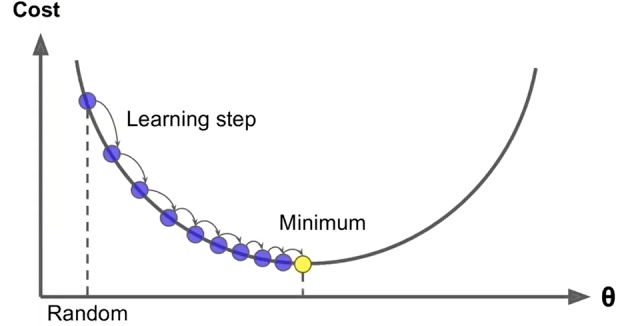
# Optimization : Gradient Descent
- To learn good word vectors: We have a cost function we want to minimize
- Gradient Descent is an algorithm to minimize by changing
- Idea: from current value of $\theta $,calculate gradient of ,then take small step in the direction of negative gradient. Repreat
Update equation (in matrix notation)
# Update equation (for a single parameter)
# code
1 | while True: |
# Stochastic gradients with word vectors (SGD)
- Iteratively (迭代地) take gradients at each such window for SGD
- But in each window, we only have at most words,so is very sparse (稀疏)!
# Solution
- We might only update the word vectors that actually appear!
- either you need sparse matrix update operations to only update certain rows of full embedding matrices U and V,or you need to keep around a hash for word vectors
- Actually ,in PyTorch, word vectors are actually represented as row vectors.
# More details
# Why there are tow vectors?
center vector and the outside vectors
To make it much easier to optimization by average both at the end.
# Two model variants:
- Skip-grams(SG)
Predict context ("outside") words (position independent) given center word - Continuous Bag of Words (CBOW)
Predict center word from (bag of) context words
# The skip-gram model with negative sample (HW2)
- The normalization term is computationally expensive
- Hence, in standard word2vec and HW2 we implement the skip-gram model with negative sampling
- So the idea of negative sampling is instead of using this softmax, we're going to train binary (二进制) logistic regression models for both the true pair of center word and the context word versus noise pairs
# Overall objective function(they maximize)
: This typically represents the output vector of a target word . In the skip-gram model of Word2Vec, the target word is the word for which we are predicting the context words.
: This represents the output vector of a context word . In negative sampling, which is often used with Word2Vec,$ j$ can refer to a negative sample (a word that is not in the context of the target word).
: This represents the input vector of a context word . In the skip-gram model, context words are the words surrounding the target word within a specified window size.
:This term maximizes the probability of the context word$ c $given the target word .
:This term deals with negative sampling. It minimizes the probability of randomly sampled words (negative samples) being in the context of the target word.
# The loss function notation more similar to class and HW2:
- We take negative samples (using word probabilities)
- Maximize probability that real outside word appears,
minimize probability that random words appear around center word. - Sample with , the unigram distribution raised to the power (We provide this function in the starter code).
- If you have a billion word corpus and a particular word occurred 90 times in it, you're taking 90 divided by billion.
- By taking threer-quarters () power, that has the effect if dampening the difference between common and rare words.
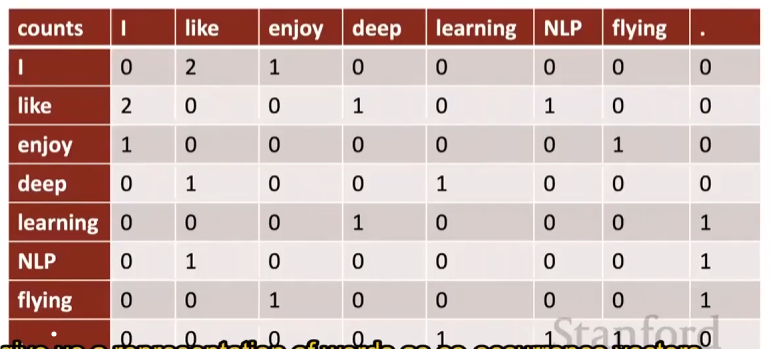
# Example : Window based co-occureence matrix
- Window length 1 (more common : 5-10)
- Symmetric (irrelevant whether left or right context)
- Example corpus:
- I like deep learning
- I like NLP
- I enjoy flying
![b478bce6325039c9b6cc414d096da7c.png]()
- To some extent that words have similar meaning and usage,so we expect them to have somewhat similar vectors.
- So if we had the word "you" as well on a larger corpus,we might expect "I" and "you" to have similar vectors because of "I like you like I enjoy you enjoy ".In this case, the sentences following "I" and "you" are the same.
# Co-occurrence vectors
- Simple count co-occurrence vectors
- Vectors increase in size with vocabulary
- Very high dimensional: require a lot of storage (though sparse)
- Subsequent classification models have sparsity issues - Models are less robust
- Low-dimensional vectors
- ldea: store “most" of the important information in a fixed, small number of dimensions: a dense vector
- Usually 25-1000 dimensions, similar to word2vec
- How to reduce the dimensionality?
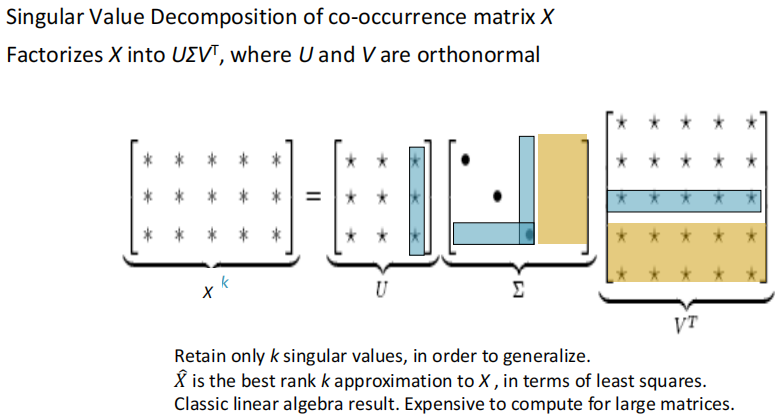
# Classic Method: Dimensionality Reduction on X(HW1)
# Some tips
# Scaling the counts in the cells can help a lot
Problem: function words (the, he, has) are too frequent àsyntax has too much impact. Some fixes:
- log the frequencies
- min(X, t), with t≈ 100
- Ignore the function words
# Ramped windows that count closer words more than further away words
# Use Pearson correlations instead of counts, then set negative values to 0
Crucial insight : Ratios of co-occurrence probabilities can encode meaning components
# Question
How can we capture ratios of co-occurrence probabilities as linear meaning components in a word vector space?
# A:
Log-bilinear model:
**with vector differences **: w_x \dot (w_a-w_b)=log \frac{P(x|a)}
# Intrinsic word vector evaluation
# Word Vector Analogies(类比)
# Meaning similarity
Another intrinsic word vector evaluation
- Word vector distances and their correlation with human judgments
- Example dataset: WordSim353 http://www.cs.technion.ac.il/~gabr/resources/data/wordsim353/
# Extrinsic word vector evaluation
One example where good word vectors should help directly: named entity recognition: identifying references to a person, organization or location: Chris Manning lives in Palo Alto.