# How do we represent the meaning of a word?
# Definition its meaning(Webster dictionary)
- the idea that is represented by a word,phrase,etc
- the idea that a person want to express by using words,signs,etc
- the idea that is expressed in a work of writing,art,etc
# commonest linguistic way of thinking of meaning:
# problems with resources like WordNet
# Great as a resource but missing nuance
- "proficient"is listed as a synonym for "good"——This is only correct in some contexts
# Missing new meanings of words
- e.g.:"wicked,badass,nifty,wizard,genius,ninja,bombest"——Nearly impossible to keep up-to-date!
# Subjective
# Requires human labor to create and adapt
# Can't compute accurate word similarity
# Representing words as discrete symbols
# regard words as discrete symbols
hotel,conference,motel - these words respect as a localist representation
such symbols for words can be represented by one-hot vectors:
Vector dimension = number of words in vocabulary
# exiting problem
example :in web search,if user searches for "Seattle motel",we would like to match documents containing "Seattle hotel"
But:
These two vectors are orthogonal (正交)
There is no natural notion of similarity for one-hot vectors!
# Solutions
- Could try to rely on WordNet's list of synonyms to get similarity ?
- But it is well-known to fail badly:incompleteness
- **Instead :learn to encode similarity in the vectors themselves **
# Representing words by their context
# Distributional 分布语义学
EXTREMELY COMPUTATIONAL
A word's meaning is given by the word's that frequently appear close-by
"You shall know a word by the company it keeps" -----which is one of the most successfully ideas of modern statistical NLP!
When a word w appears in a text,its context is the set of words that appear nearby (within a fixed-size window)
Use the many contexts of w to build up a representation of w
- the context words will represent banking!
Find out a bunch of places where banking occurs in text,and will collect the sort of nearby words that context words.
When talking about a word in our natural language,we sort of have two senses of word which are referred to as types and tokens.
# Word vectors
build a vector for each word,chosen so that it is similar to vectors of words that appear in similar contexts.
Note: word vectors are also called word embeddings or (neural) word representations
# Word2vec
# Idea
- We have a large corpus (语料) ("body") of text
- Every word in a fixed vocabulary is represented by a vector
- Go through each position t in the text,which has a center word c and context ("outside") words o
- Use the similarity of the word vectors for c and o
- Keep adjusting the word vectors to maximize this probability
# Overview
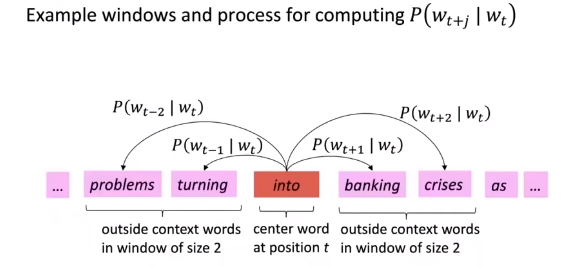
- choose the center word into and analyze its context
- If a model of predicting the probability of context words given the center word and this mode,we'll come to in a minute.
- So,we need to find out what probability it gives to the words that actually occurred in the context of this word.
# problem
How can we work out the probability of a word occurring in the context of the center word?
# model
fixed: 固定的 likelihood: 可能性 variables: 变量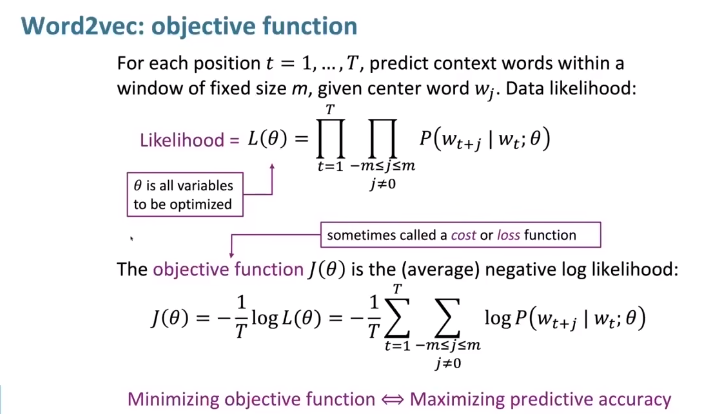
That's the setup,but how do we calculate the probability of a word occurring in the context?

The only thing we ought to do is to have vector representations for each word,and we're going to work out the probability simply in terms of the word vectors.
# prediction function

# Train the model
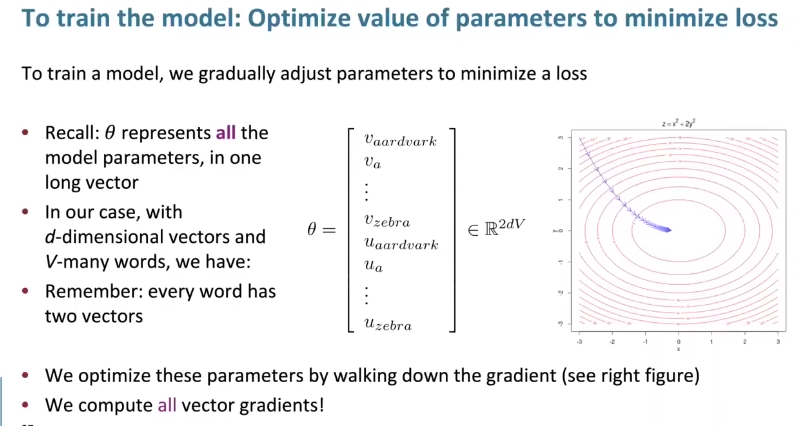
How to train the model?**We wanna to minimize our loss by fiddle our word vectors **.And maximize the probability of the words we actually saw in the context of the center word.
- Remember! Each word have two vectors, its context vector and its center vector.
- And below we put on the loss function
Following are the softmax function:
And the partial derivative is :