1 | import numpy as np |
# 本项目参考学习文档为斯坦福计算机深度学习课程 —— 用于视觉识别的 CS231n 卷积神经网络
曼哈顿距离: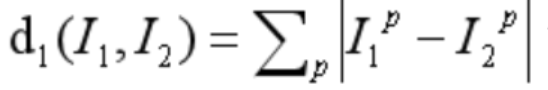 ,其中 I1 和 I2 是两幅图像,I1P 和 I2P 分别是 I1 和 I2 在位置 P 的像素值。差异矩阵也是像素点依次相减。通过衡量图像像素点的绝对值差之和差异性来
,其中 I1 和 I2 是两幅图像,I1P 和 I2P 分别是 I1 和 I2 在位置 P 的像素值。差异矩阵也是像素点依次相减。通过衡量图像像素点的绝对值差之和差异性来
对于该预测方法还有 L2 距离,其定义为: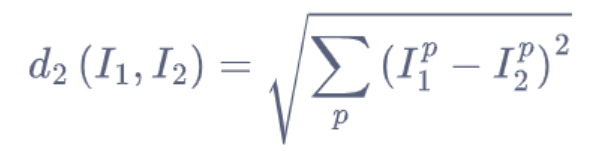
最近临分类器:
(1)训练:将训练数据存储在实际变量中。
(2)预测:对每一个测试样本,计算其与训练样本 L1 的距离,找到距离最近的训练样本,将该训练样本的标签作为测试样本的预测标签。
* 训练方法 :def train (self, X, y): X(训练数据,形状为 ND,每一行都是一个样本)和 y(训练标签,大小为 N 的一维数组), 然后存储在 self 类中。
self.Xtr = X
self.ytr = y
预测方法
predict 方法接受一个参数 x*(测试数据,形状为 N*D,每一行都是一个需要预测的样本)*
num_test 表示测试样本的数量
Ypred 初始化为零数组 np.zeros(num_test,dtype=self.ytr.dtype) , 前者表示数组的长度,即为包含元素的个数;后者是一个关键词参数,指定数组中的数据类型设置为与 self.ytr 数组的数据类型相同。dtype 是数据类型的缩写。
对于每个测试样本,计算它与所有训练样本的 L1 距离:
1 | distances = np.sum(np.abs(self.Xtr - X[i,:]), axis=1) |
- 通过取绝对值差的和计算 L1 距离。
self.Xtr - X[i,:]计算每个训练样本与第i个测试样本的差值。(这里self.Xtr是一个矩阵,X[i,:]是一个向量X[i,:]表示矩阵X的第i行)self.Xtr - X[i,:]计算的是矩阵self.Xtr中的每一行向量减去向量X[i,:]的结果。np.abs(self.Xtr - X[i,:]):对上述差值矩阵中的每个元素取绝对值,得到一个与self.Xtr形状相同的矩阵。np.sum(..., axis=1)对每个样本的所有特征求和,得到每个训练样本与该测试样本的距离。- 通过
min_index = np.argmin(distances)找到距离最小的样本 (np.argmin: 返回最小距离对应的索引)
Q: With N examples, how fast are training and prediction?
- 问题:对于 N 个样本,训练和预测的速度(效率)是多少?
A: Train O(1), predictO(N)
回答:训练时间复杂度是 O (1),预测时间复杂度是 O (N)。
训练时间复杂度 O (1):训练阶段只需记住所有训练数据,不需要复杂计算,所以训练时间是常数时间,即与训练样本的数量 N 无关。
预测时间复杂度 O (N):预测阶段,对于每个测试样本,需要计算其与所有训练样本的距离,并找到最近的那个训练样本。因此,预测时间与训练样本的数量 N 成正比。
Q:This is bad: we want classifiers that are fast at prediction; slow for training is ok
- 为什么这是不好的设计?
A: 这是不好的设计:我们希望分类器在预测时速度快;在训练时速度慢是可以接受的。
- 在实际应用中,预测阶段通常比训练阶段更频繁。例如,一个已经训练好的分类器可能需要处理大量的实时预测请求。如果预测速度很慢,会严重影响系统的性能和用户体验。
- 训练阶段可以相对较慢,因为训练通常是一个离线过程,可以在后台完成,不直接影响用户体验。
# 总结
最近邻分类器的一个主要缺点是它的预测阶段计算量大,对于每个测试样本需要计算其与所有训练样本的距离,因此预测速度较慢。这在需要快速响应的应用中是一个很大的问题,而对于训练阶段的速度要求则相对宽松。因此,更理想的分类器设计是训练阶段可以慢一些,但预测阶段必须非常快。
# K - 最近临法
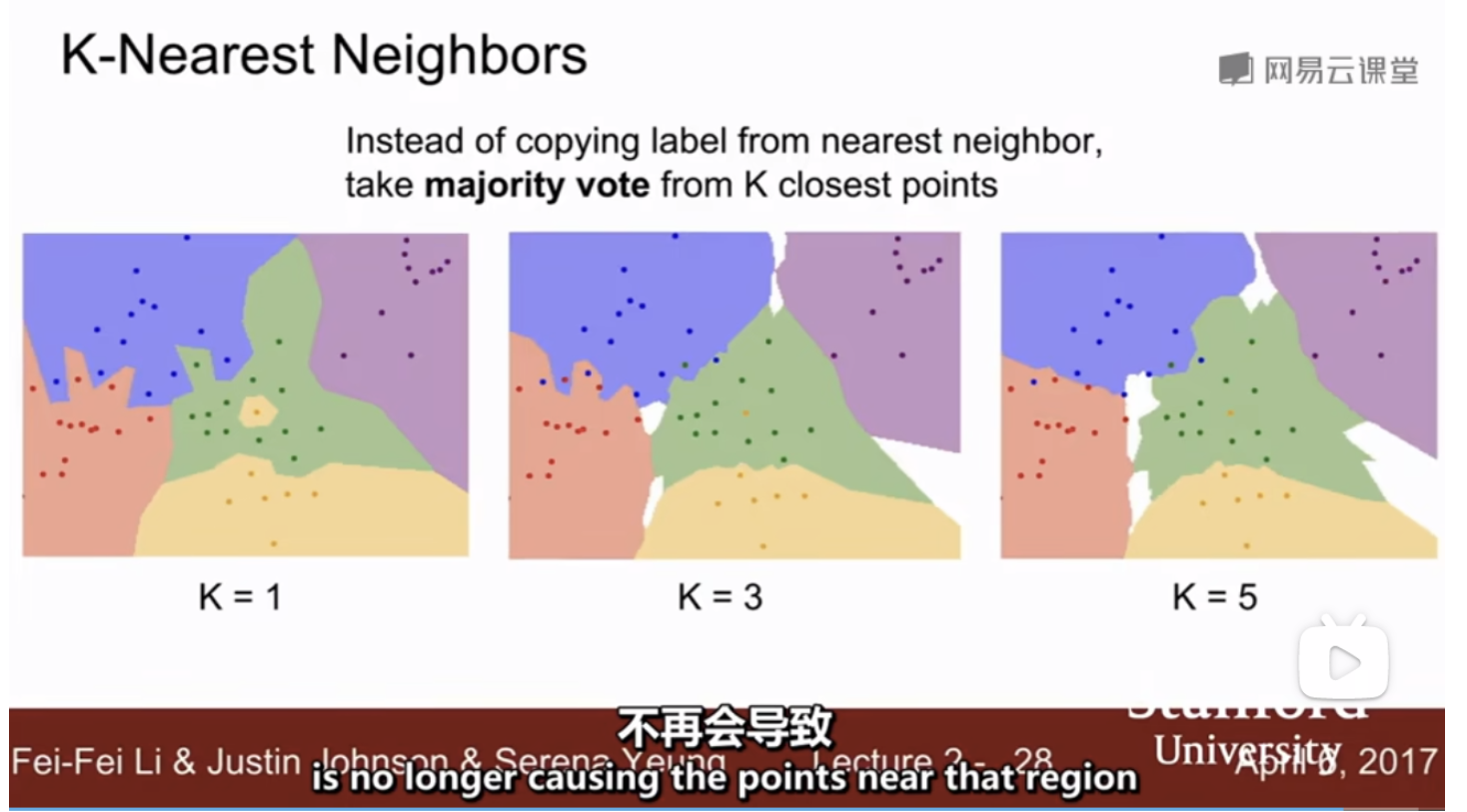
图中展示的是 K - 最近邻(K-Nearest Neighbors, K-NN)分类器的基本原理和效果。K-NN 分类器是一个简单但非常有效的分类算法,它的核心思想是根据一个样本的 K 个最近邻居来确定其类别。具体来说,这里通过 K 个最近邻居的多数投票来决定样本的分类。
白色区域:这个区域没有进行 k - 最近投票
k=1:
- 当 K=1 时,分类器仅考虑与样本最近的一个邻居。这个邻居的类别直接决定了样本的类别。虽然这种方法非常直接和简单,但它容易受噪声和孤立点的影响,导致分类效果不稳定。
k=3:
- 当 K=3 时,分类器考虑与样本最近的三个邻居。样本的类别由这三个邻居的多数投票决定。相比于 K=1,这种方法更加鲁棒,能够更好地抵御噪声的影响。但是,它仍然可能受少数几个错误邻居的影响。
k=5:
- 当 K=5 时,分类器考虑与样本最近的五个邻居。样本的类别由这五个邻居的多数投票决定。进一步增加 K 值,分类器变得更加稳定,因为它综合了更多邻居的信息,减少了单个噪声点对分类结果的影响。然而,如果 K 值过大,分类器可能会包含过多不相关的邻居信息,导致分类结果不准确。
# 主要思想
- 多数投票:K-NN 分类器的核心思想是 “多数投票”,即根据 K 个最近邻居中出现频率最高的类别来决定样本的类别。
- 距离度量:K-NN 分类器依赖于距离度量来确定最近的 K 个邻居。常用的距离度量方法包括欧氏距离、曼哈顿距离等。
- 参数选择:K 值的选择对分类效果有重要影响。K 值太小容易受噪声影响,K 值太大则可能引入过多无关信息。
# 接下来我们以 CIFAR-10 数据集的结果来进行代码编写
1 | import numpy as np |
k-NN 阶段实现了一个简单的 k 近邻(k-Nearest Neighbors, k-NN)分类器,使用了 L1 距离(曼哈顿距离)和 L2 距离(欧几里得距离)
代码注释已列与代码中