# 卷积神经网络

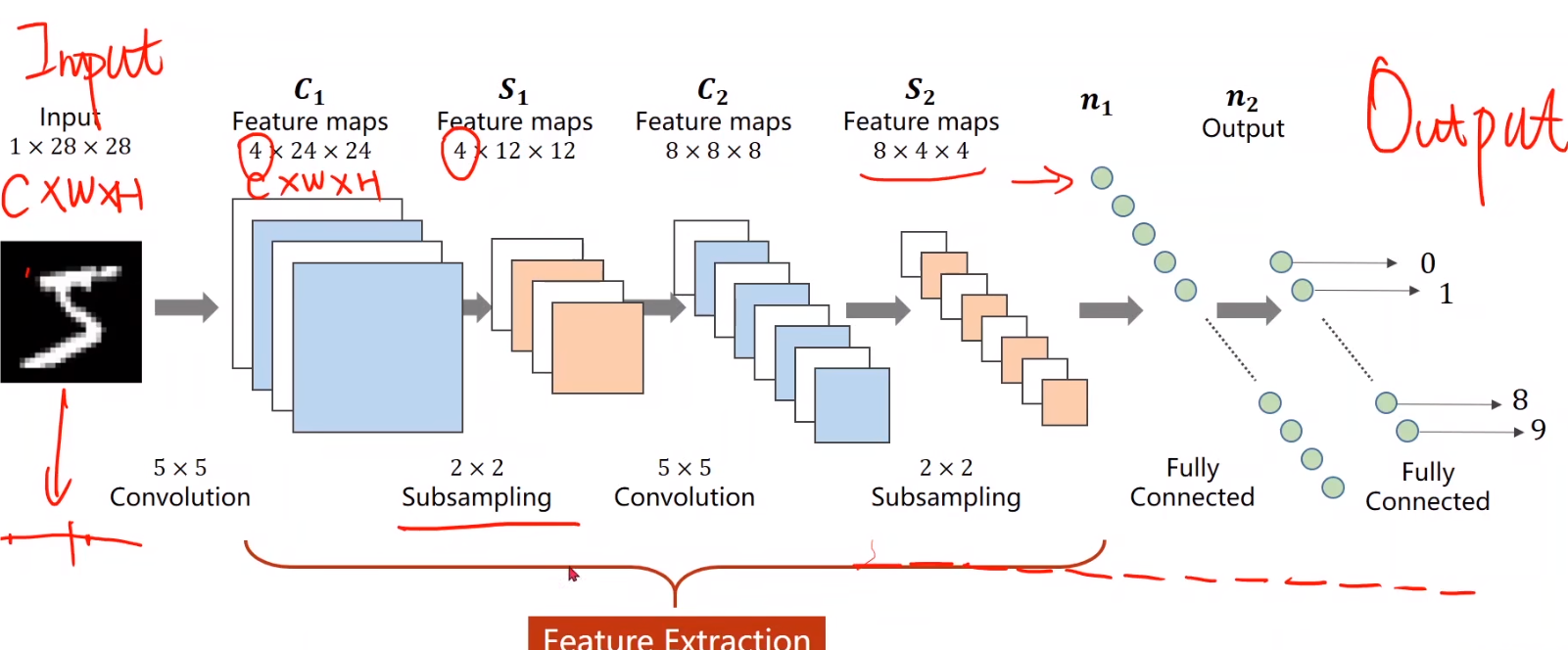
# 输入层
输入:图像大小为 ,其中 1 表示图像的通道数(灰度图像), 表示图像的宽度和高度。
# 卷积层
卷积核,也称为滤波器(filter),是卷积神经网络(CNN)中的一个小矩阵,用来对输入图像进行卷积操作,从而提取特征。
卷积操作:对输入图像应用卷积核,通常用 5x5 的卷积核,这里得到的特征图(Feature maps)大小为 ,其中 4 是卷积核的数量(也就是产生的特征图数量),24 是卷积后的宽度和高度(由于卷积操作会减小尺寸)。
特征图:表示从图像中提取的特征,通过卷积操作得到。
# 下采样层 S1
- 下采样是一种减少特征图尺寸的方法,同时保留重要特征。最常见的下采样方法是池化,包括最大池化(Max Pooling)和平均池化(Average Pooling)。
- 最大池化(Max Pooling):选择池化窗口中的最大值。例如,使用 $ 2 \times 2 2 \times 2 $ 区域中的最大值作为输出。
- 平均池化(Average Pooling):选择池化窗口中的平均值,类似于最大池化,但取平均值。
- 下采样(Subsampling):通常使用最大池化(Max Pooling)或平均池化(Average Pooling),这里使用 2x2 的池化核,对 C1 层的特征图进行下采样,得到 的特征图。
- 作用:减少特征图的尺寸,降低计算量,同时保留重要特征。
# 卷积层 C2
- 卷积操作:再次应用卷积核,这里使用 5x5 的卷积核,得到的特征图大小为 ,其中 8 是卷积核的数量。
- 特征图:进一步提取更高层次的特征。
# 下采样层 S2
- 下采样(Subsampling):同样使用 2x2 的池化核,对 C2 层的特征图进行下采样,得到 8×4×4 的特征图。
- 作用:进一步减少特征图的尺寸,降低计算量。
# 全连接层 n1 和 n2
Flattening:将多维的特征图展开成一维向量,准备输入到全连接层中。
全连接层 n1:连接所有输入神经元到输出神经元,这里假设有若干个神经元。
全连接层 n2:最终输出层,通常有 10 个神经元,对应 10 个分类(数字 0 到 9)。
# 输出层 / 分类器
- 输出:每个神经元表示输入图像属于某一类的概率,输出的维度是 10,对应 10 个类别。
# 总结
- 特征提取(Feature Extraction):通过卷积层和下采样层提取图像的特征。
- 分类(Classification):通过全连接层对提取的特征进行分类。
# 介绍
# 颜色通道
一个图像通常由红绿蓝三个通道组成,也就是 RGB 里的 Red、Green、Blue
分为 Input Channel、Width 和 Height
# Patch
在计算机视觉和图像处理领域,“Patch” 通常指的是图像中的一个小区域或子块。Patch 可以用于各种任务,例如特征提取、图像分割、图像修复等。
# 卷积的运算过程
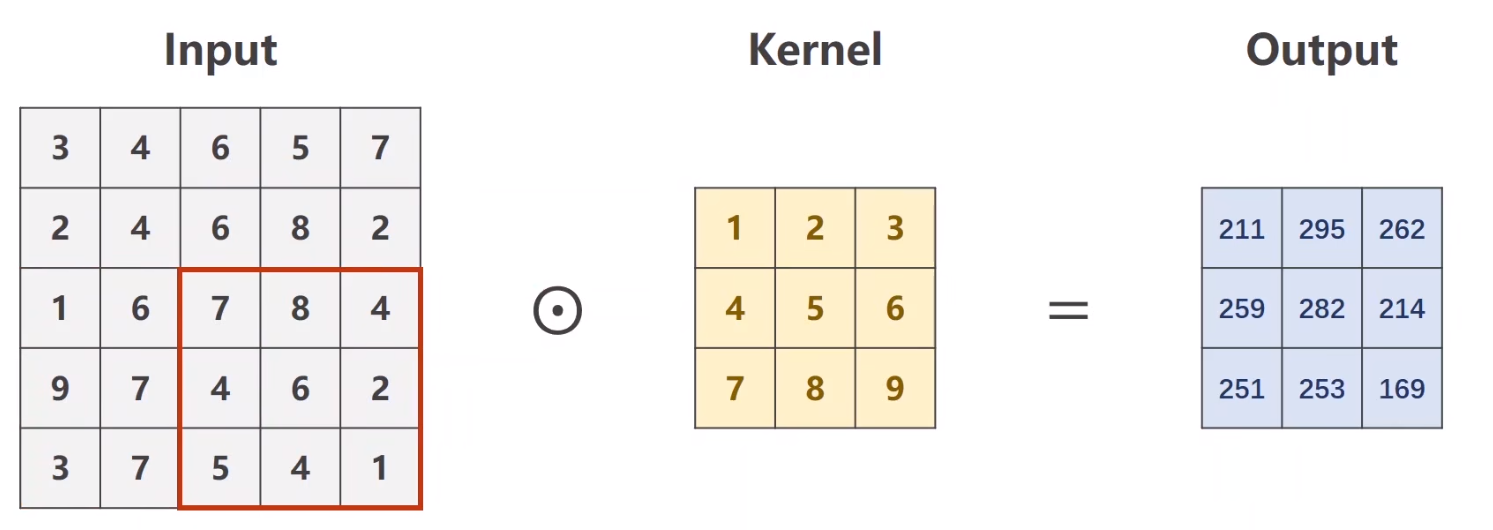
假设有一个 5×5 的输入,3×3 的核要做卷积。(矩阵的向量积:对应的位置数量相乘然后相加)
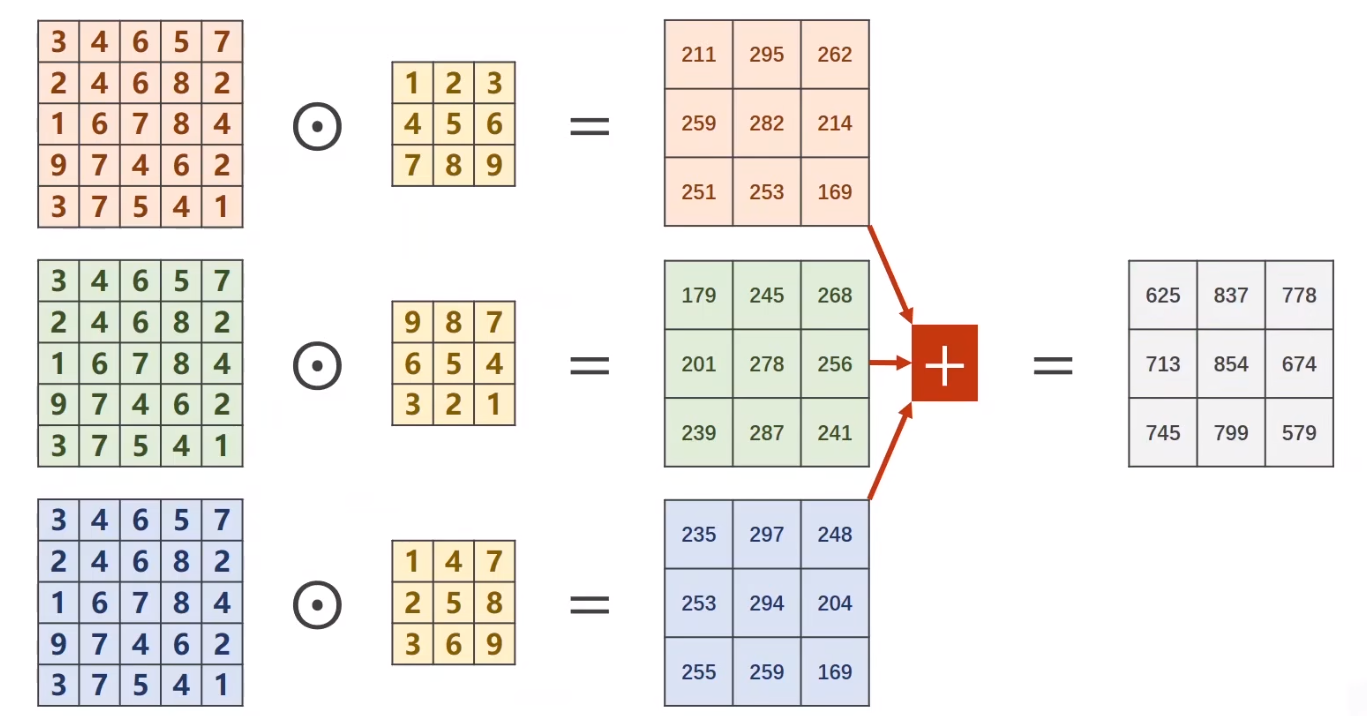
有几个通道,卷积核就应该是几个
不同通道卷积后最终的 Output 再在对应的位置相加
![QQ_1722186740147.png]()
# 应用于多个 Patch 时,流程图如下
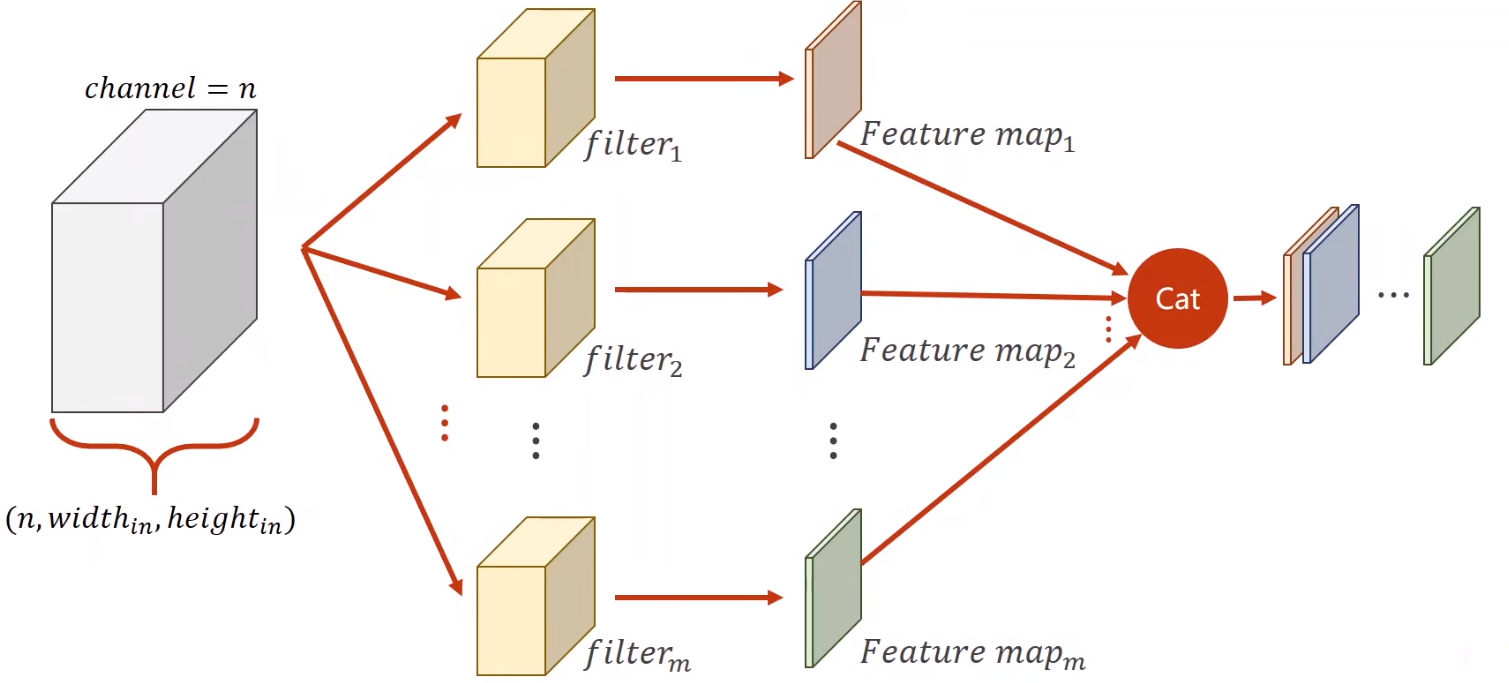
# 将结果拼接成四维输出

- 左侧的立方体表示输入张量,大小为 。
- 中间的部分说明了每个卷积层需要 $ m n \times \text {kernel_size}{\text{width}} \times \text{kernel_size}{\text{height}}$。
- 右侧的立方体表示输出特征图,大小为 。
# 重点:图中四维张量的解释
图中间部分显示了四维度张量的结构:
- 每个卷积核的大小是
- 有 $$m$$ 个这样的卷积核,因此整个卷积层的权重可以表示为一个四维张量,大小为
# 代码实现
1 | import torch |
in_channels:输入通道数,这里设为 5。out_channels:输出通道数,这里设为 10。width和height:输入图像的宽度和高度,都设为 100。kernel_size:卷积核的大小,这里设为 3(即 3×33 \times 33×3 的卷积核)。batch_size:批量大小,这里设为 1。使用
torch.randn函数生成一个随机张量,模拟输入数据。张量的形状为(batch_size, in_channels, width, height),即(1, 5, 100, 100)。使用
torch.nn.Conv2d定义一个二维卷积层。该卷积层将输入的 5 个通道转换为 10 个通道,卷积核大小为将输入数据传递给卷积层,得到输出张量。
# Padding
Padding(填充)在卷积神经网络(CNN)中的作用是通过在输入图像的边缘添加额外的像素,以控制卷积操作后的输出特征图的空间尺寸。Padding 有几种常见的方式,包括零填充、反射填充和重复填充。以下是 Padding 的主要作用和实现方式的详细介绍:
# Padding 的作用
- ** 控制输出尺寸:** 在卷积操作中,不使用填充会导致输出特征图的尺寸减小。例如,一个 的卷积核在一个 的输入图像上滑动,输出特征图的尺寸将变为。使用 Padding 可以保持输出特征图的尺寸与输入图像相同。
- 保留边界信息:边界像素在卷积操作中被处理的次数较少,不使用填充会导致边界信息的丢失。Padding 可以确保边界像素也能参与到卷积操作中,从而保留更多的边界信息。
- 增强特征提取效果:在卷积层的多个滤波器中,添加 Padding 可以让滤波器的感受野(即卷积核覆盖的输入区域)更好地覆盖整个输入图像,从而提取更多的特征。
# Padding 类型
零填充(Zero Padding):在输入图像的边缘添加值为零的像素。这是最常用的一种填充方式。
1
conv_layer = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
反射填充(Reflection Padding):在输入图像的边缘添加反射后的像素值。
1
2
3
4padding = torch.nn.ReflectionPad2d(1)
input_padded = padding(input)
conv_layer = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3)
output = conv_layer(input_padded)重复填充(Replication Padding):在输入图像的边缘添加重复的像素值。
1
2
3
4padding = torch.nn.ReplicationPad2d(1)
input_padded = padding(input)
conv_layer = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3)
output = conv_layer(input_padded)# 示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import torch
input = [
3, 4, 6, 5, 7,
2, 4, 6, 8, 2,
1, 6, 7, 8, 4,
9, 7, 4, 6, 2,
3, 7, 5, 4, 1
]
input = torch.Tensor(input).view(1, 1, 5, 5) # B C W H
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False) # padding=1,填充一圈 bias=False:不加偏置
kernel = torch.Tensor([
1, 2, 3,
4, 5, 6,
7, 8, 9
]).view(1, 1, 3, 3) #改形状(Output,Input,Weight,Height)
conv_layer.weight.data = kernel.data
output = conv_layer(input)
print(output)
# stride
表示每次卷积核移动时的步长 —— 可以有效降低图像里的宽度和高度
# maxpooling
MaxPooling(最大池化)是卷积神经网络(CNN)中常用的一种下采样技术,用于减少特征图的尺寸,同时保留最重要的特征。最大池化操作通过取池化窗口中的最大值来实现,它能够有效地减小计算量,控制过拟合,并且增强模型的鲁棒性。以下是对 MaxPooling 技术的详细介绍:
# MaxPooling 的定义和作用
# 定义
- MaxPooling 通过在特征图上滑动一个固定大小的窗口(通常是 2x2 或 3x3),在每个窗口内取最大值,生成一个新的、尺寸更小的特征图。
# 作用
- 尺寸缩减:减少特征图的空间尺寸,从而减少参数数量和计算量。
- 保留最重要的特征:通过取每个池化窗口内的最大值,保留局部区域内最强的激活值,从而保留重要的特征。
- 位置不变性:通过池化操作,模型对输入的微小变化(如平移、旋转等)更加鲁棒。
# 示例代码
1 | import torch |

1 | import torch |
self.conv1 = nn.Conv2d(1, 10, kernel_size=5) :定义第一个卷积层,输入通道为 1,输出通道为 10,卷积核大小为 5x5。
self.conv2 = nn.Conv2d(10, 20, kernel_size=5) :定义第二个卷积层,输入通道为 10,输出通道为 20,卷积核大小为 5x5。
self.pooling = nn.MaxPool2d(2) :定义最大池化层,池化窗口大小为 2x2。
self.fc = nn.Linear(320, 10) :定义全连接层,输入大小为 320,输出大小为 10。
x = x.view(batch_size, -1) :将卷积层输出的多维张量展平成一维张量。这行代码用于将张量 x 展平为一维张量,其中 -1 是一个特殊的值,表示自动计算维度的大小。
# Advanced CNN
Inception 模块通过多种不同尺寸的卷积核和池化操作来提取多尺度的特征,进而提高网络的表现力和效率。
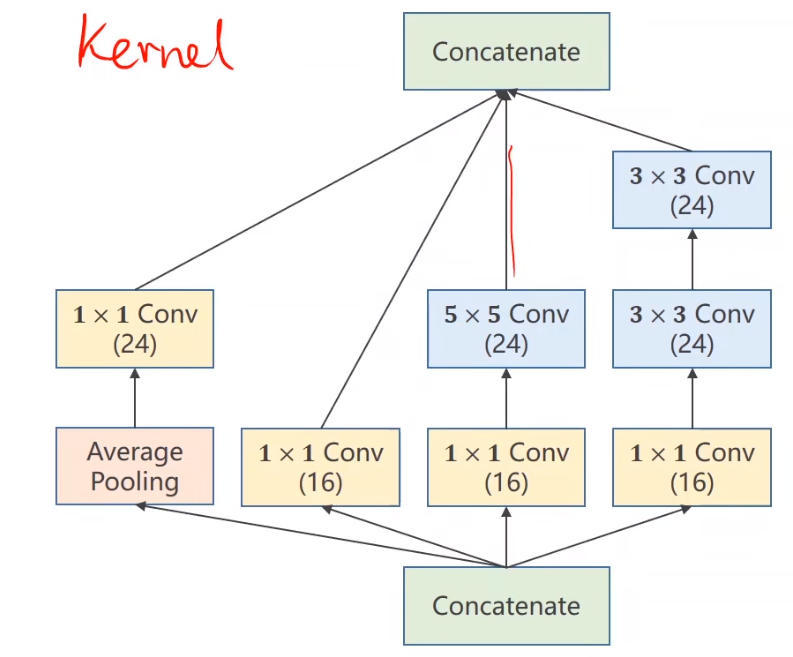
1x1 卷积(Conv):这些卷积操作用 1x1 的卷积核进行卷积。1x1 卷积主要用于减少维度,即通道数的降维,从而降低计算复杂度和参数数量。
3x3 卷积(Conv):这些卷积操作用 3x3 的卷积核进行卷积,用于提取局部的空间特征。
5x5 卷积(Conv):这些卷积操作用 5x5 的卷积核进行卷积,用于提取更大范围的空间特征。
平均池化(Average Pooling):这一操作对输入进行平均池化,然后通过 1x1 卷积进一步处理。池化操作用于减少特征图的空间尺寸,同时保留主要特征。
串联(Concatenate):各条路径的输出在通道维度上进行串联(拼接),形成最终的输出特征图。
# 卷积瓶颈
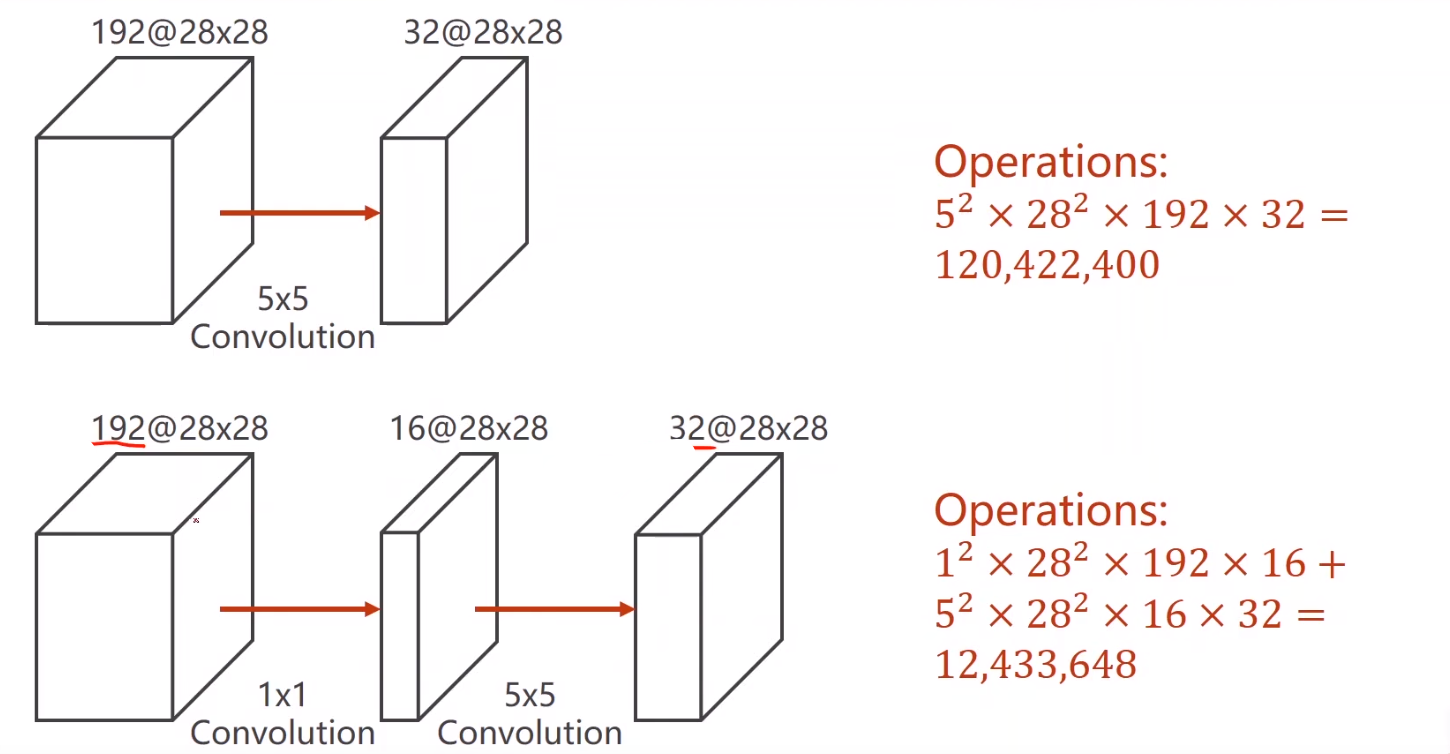

# 代码实现
# 平均池化
1 | self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1) |
avg_pool2d: 平均池化函数
# 池化一(16 通道 1*1)
1 | self.branch1x1=nn.Conv2d(in_channels,16,kernel_size=1) |
# 法三:1*1 的卷积接 5*5 的卷积
1 | self.branch5×5_1=nn.Conv2d(in_channels,16,kernel_size=1) |
# 法四:1×1 接 3×3 接 3×3
1 | self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1) |
# 拼接
1 | outputs=[branch1×1,branch5×5,branch3×3,branch_pool] |
# 完整代码
1 | import torch |
# 残差神经网络
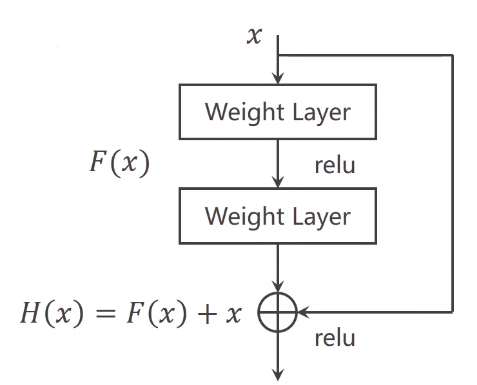
- 输入 经过两层加权层,每层后面接一个 ReLU 激活函数。
- 同时,输入 直接跳跃(skip connection)到输出处,并与通过加权层后的输出相加。
- 计算公式为:
- 其中
- 这种结构通过直接连接输入和输出,形成一个捷径路径,使得梯度能够更容易地反向传播。
# 代码实现
1 | import torch |
- 输入
x通过第一个卷积层conv1,并通过 ReLU 激活函数,结果存储在y中。 - 然后,
y通过第二个卷积层conv2。 - 最后,将输入
x和通过两个卷积层的输出y相加,并通过 ReLU 激活函数,返回最终的输出。
# 完整代码引用
1 | import torch |