# 如何实现多分类问题?
# 概率分布
- 每个可能的输出概率都需要大于等于零
- 所有可能分类概率之和为 1
# 函数区别
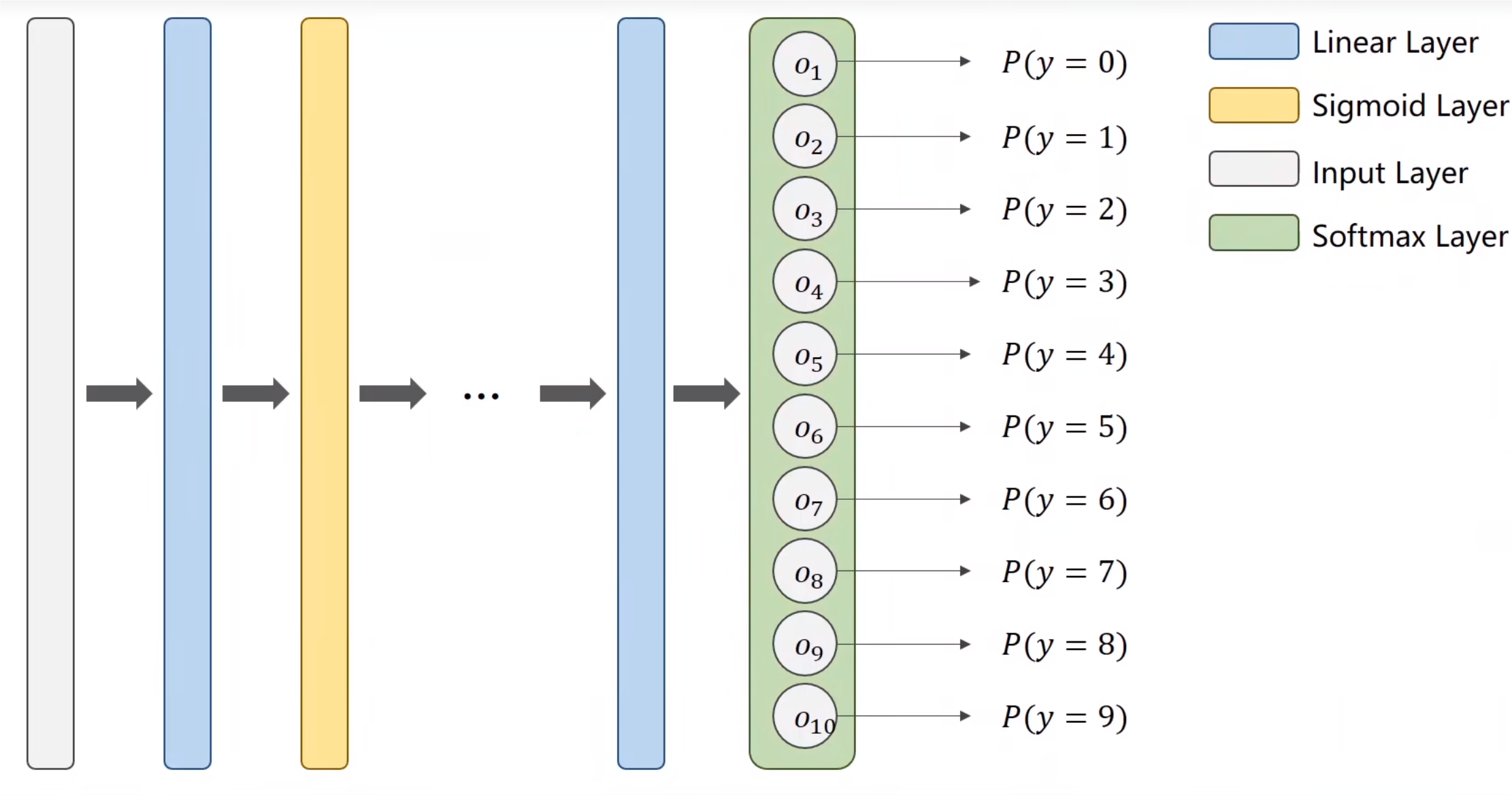
- 中间处理过程可以用 Sigmoid 函数
- 最终层应该为 Softmax 层
# Softmax 实现

# One-hot 方法
One-hot 编码是一种将分类数据转换为二进制向量的方法,通常用于将离散的分类标签转换为机器学习算法可以处理的格式。每个类别用一个独特的二进制向量表示,其中只有一个位置的值为 1,其余位置的值为 0。这样做的好处是可以将分类数据转化为数值数据,方便模型处理。
# 损失函数求法
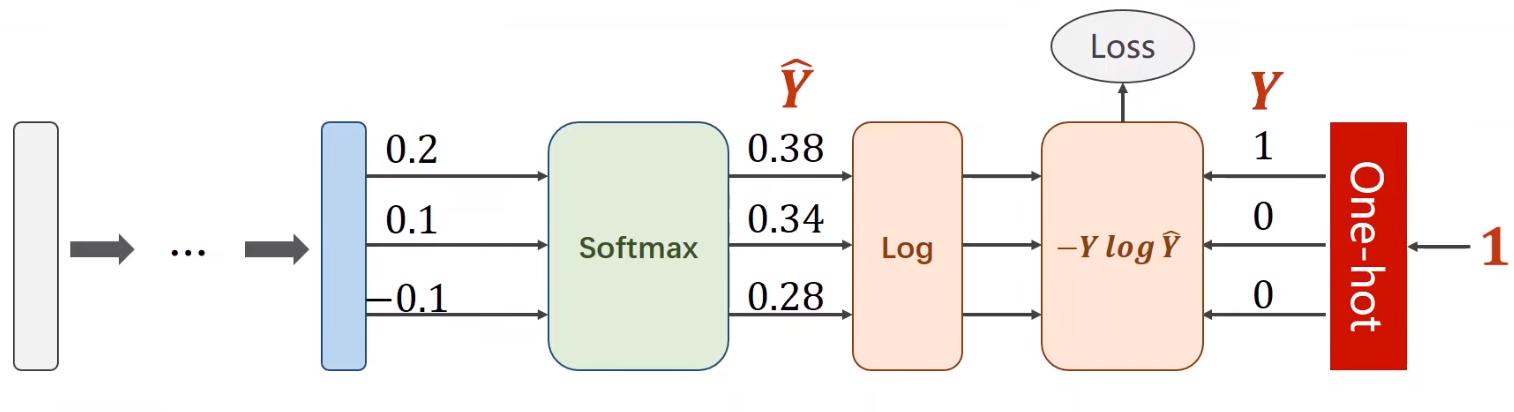
# 代码实现
# numpy 格式
1 | import numpy as np |
# torch 实现
1 | import torch |
- 输出的最后一层不要进行激活 —— 即最后一层输出不要进行非线性变换
- 损失函数用
CrossEntropyLoss()库实现
# 多分类问题代码
# 引用相关库
1 | import torch |
# 数据处理
1 | batch_size = 64 |
transforms.ToTensor(): 这个操作将图像从 PIL 图像或者 numpy 数组转换为 PyTorch 张量(Tensor)。在转换过程中,它还会将图像的像素值从 0-255 缩放到 0-1 之间。这个步骤是必要的,因为 PyTorch 模型需要张量格式的数据作为输入。transforms.Normalize((0.1307,), (0.3081,)): 这个操作对图像进行标准化处理。标准化是通过减去均值并除以标准差来完成的,这样可以使数据具有零均值和单位方差。对于 MNIST 数据集,经验上得出的像素值均值为 0.1307,标准差为 0.3081。这个步骤可以加速模型的训练收敛,并提高模型的泛化能力。- pytorch 中将 转为,以便高效运算。
- 故此处的
transform将 转换为. 其中。 - 数据标准化:Pixel_{norm}=\frac{Pixel_{origin}-mean}
# 用 relu 库来预测
1 | import torch |
在优化器中,
momentum是一个加速梯度下降过程的技术。具体来说,momentum是用来减少训练过程中震荡的一种方法,可以加快收敛速度。详细解释
在梯度下降中,更新权重的公式通常是:
其中:
- 是权重。
- 是学习率。
- ) 是损失函数对权重的梯度。
引入动量后,权重的更新公式变为:
其中:
- 是第 次更新时的动量项。
- 是动量系数(通常在 0 到 1 之间,图中为 0.5)。
- 是前一次更新时的动量项。
动量的引入使得每次更新不仅依赖当前的梯度,还会考虑前一次更新的方向,从而能够平滑梯度更新的路径,减少梯度下降过程中的震荡。动量项在梯度方向保持一致时,会加快收敛速度,而在梯度方向发生变化时,会起到抑制作用,从而使得更新更加平滑。
relu 函数:
# 完整代码
1 | import torch |
x = x.view(-1, 784):将输入的图像展平成大小为(-1, 784)的二维张量(-1 表示自动计算维度大小)。x = F.relu(self.l1(x)):将输入传递给第一层,并应用 ReLU 激活函数。x = self.l5(x):将第四层的输出传递给第五层(没有激活函数,因为这是最终输出层)。- 创建一个
Net类的实例,即初始化神经网络模型。 - 定义损失函数为交叉熵损失,用于多分类任务。
- 定义优化器为随机梯度下降(SGD),学习率为 0.01,动量为 0.5。
running_loss = 0.0:初始化累积损失为 0。for batch_idx, data in enumerate(train_loader, 0):遍历训练数据加载器。inputs, target = data:将数据分为输入inputs和目标target。optimizer.zero_grad():清除优化器的梯度。outputs = model(inputs):将输入传入模型,得到输出outputs。loss = criterion(outputs, target):计算损失。loss.backward():反向传播,计算梯度。optimizer.step():更新模型参数。running_loss += loss.item():累加损失。if batch_idx % 300 == 299:每 300 个批次打印一次平均损失。print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300)):打印当前轮次和批次的平均损失。running_loss = 0.0:重置累积损失。