# 矩阵求导的书matrix.cookbook
# 线性模型分为训练集( x , y ) (x,y) ( x , y ) ( x , ? ) (x,?) ( x , ? )
# 损失函数l o s s = ( y ^ − y ) 2 = ( x ∗ ω − y ) 2 loss=(\hat{y}-y)^2=(x*\omega-y)^2 l o s s = ( y ^ − y ) 2 = ( x ∗ ω − y ) 2
# Mean Square Error 平均平方误差c o s t = 1 N ∑ n = 1 N ( y ^ ^ n − y n ) 2 cost=\frac1N\sum_{n=1}^N(\hat{\hat{y}}_n-y_n)^2 c o s t = N 1 n = 1 ∑ N ( y ^ ^ n − y n ) 2
# 代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import numpy as npimport matplotlib.pyplot as pltx_data = [1.0 , 2.0 , 3.0 ] y_data = [2.0 , 4.0 , 6.0 ] def forward (x ): return x * w def loss (x, y ): y_pred = forward(x) return (y_pred - y) * (y_pred - y) w_list = [] mse_list = [] for w in np.arange(0.0 , 4.1 , 0.1 ): print ('w=' , w) l_sum = 0 for x_val, y_val in zip (x_data, y_data): y_pred_val = forward(x_val) loss_val = loss(x_val, y_val) l_sum += loss_val print ('\t' , x_val, y_val, y_pred_val, loss_val) print ('MSE=' , l_sum / 3 ) w_list.append(w) mse_list.append(l_sum / 3 )
# 梯度下降法梯度: ∂ c o s t ∂ ω 梯度:\frac{\partial cost}{\partial\omega} 梯 度 : ∂ ω ∂ c o s t
根据梯度的变化来灵活调整学习率:
ω ‾ = ω ‾ − α ‾ ∂ c o s t ∂ ω \underline{\omega}=\underline{\omega}-\underline{\alpha}\frac{\partial cost}{\partial\omega} ω = ω − α ∂ ω ∂ c o s t
但是这样只能找到局部最优,找不到全局最优
鞍点 :梯度等于零
# 梯度下降发应用于损失函数∂ c o s t ( ω ) ∂ ω = ∂ ∂ ω 1 N ∑ n = 1 N ( x n ⋅ ω − y n ) 2 = 1 N ∑ n = 1 N ∂ ∂ ω ( x n ⋅ ω − y n ) 2 = 1 N ∑ n = 1 N 2 ⋅ ( x n ⋅ ω − y n ) ∂ ( x n ⋅ ω − y n ) ∂ ω = 1 N ∑ n = 1 N 2 ⋅ x n ⋅ ( x n ⋅ ω − y n ) \begin{aligned} \frac{\partial cost(\omega)}{\partial\omega}& =\frac\partial{\partial\omega}\frac1N\sum_{n=1}^N(x_n\cdot\omega-y_n)^2 \\ &=\frac1N\sum_{n=1}^N\frac\partial{\partial\omega}(x_n\cdot\omega-y_n)^2 \\ &=\frac{1}{N}\sum_{n=1}^{N}2\cdot(x_{n}\cdot\omega-y_{n})\frac{\partial(x_{n}\cdot\omega-y_{n})}{\partial\omega} \\ &=\frac1N\sum_{n=1}^N2\cdot x_n\cdot(x_n\cdot\omega-y_n) \end{aligned} ∂ ω ∂ c o s t ( ω ) = ∂ ω ∂ N 1 n = 1 ∑ N ( x n ⋅ ω − y n ) 2 = N 1 n = 1 ∑ N ∂ ω ∂ ( x n ⋅ ω − y n ) 2 = N 1 n = 1 ∑ N 2 ⋅ ( x n ⋅ ω − y n ) ∂ ω ∂ ( x n ⋅ ω − y n ) = N 1 n = 1 ∑ N 2 ⋅ x n ⋅ ( x n ⋅ ω − y n )
# 对于前文函数的梯度下降算法ω = ω − α 1 N ∑ n = 1 N 2 ⋅ x n ⋅ ( x n ⋅ ω − y n ) \omega=\omega-\alpha\frac1N\sum_{n=1}^N2\cdot x_n\cdot(x_n\cdot\omega-y_n) ω = ω − α N 1 n = 1 ∑ N 2 ⋅ x n ⋅ ( x n ⋅ ω − y n )
# 代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 x_data = [1.0 , 2.0 , 3.0 ] y_data = [2.0 , 4.0 , 6.0 ] w = 1.0 def forward (x ): return x * w def cost (xs, ys ): cost = 0 for x, y in zip (xs, ys): y_pred = forward(x) cost += (y_pred - y) ** 2 return cost / len (xs) def gradient (xs, ys ): grad = 0 for x, y in zip (xs, ys): grad += 2 * x * (x * w - y) return grad / len (xs) print ('Predict (before training)' , 4 , forward(4 ))for epoch in range (100 ): cost_val = cost(x_data, y_data) grad_val = gradient(x_data, y_data) w -= 0.01 * grad_val print ('Epoch:' , epoch, 'w=' , w, 'loss=' , cost_val) print ('Predict (after training)' , 4 , forward(4 ))
w 是线性模型的初始权重cost(xs,ys) 是损失函数gradients 梯度函数:先把∑ n = 1 N 2 ⋅ x n ⋅ ( x n ⋅ ω − y n ) \sum_{n=1}^N2\cdot x_n\cdot(x_n\cdot\omega-y_n) ∑ n = 1 N 2 ⋅ x n ⋅ ( x n ⋅ ω − y n ) 将1 N ∑ n = 1 N 2 ⋅ x n ⋅ ( x n ⋅ ω − y n ) \frac1N\sum_{n=1}^N2\cdot x_n\cdot(x_n\cdot\omega-y_n) N 1 ∑ n = 1 N 2 ⋅ x n ⋅ ( x n ⋅ ω − y n ) grad_val = gradient(x_data, y_data) 表示 最后进行训练迭代
# 随机梯度下降ω = ω − α ∂ l o s s ∂ ω \omega=\omega-\alpha\frac{\partial loss}{\partial\omega} ω = ω − α ∂ ω ∂ l o s s
拿单个样本的损失函数对权重求导然后更新 —— 更加灵活。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 x_data = [1.0 , 2.0 , 3.0 ] y_data = [2.0 , 4.0 , 6.0 ] w = 1.0 def forward (x ): return x * w def loss (x, y ): y_pred = forward(x) return (y_pred - y) ** 2 def gradient (x, y ): return 2 * x * (x * w - y) print ('Predict (before training)' , 4 , forward(4 ))for epoch in range (100 ): for x, y in zip (x_data, y_data): grad = gradient(x, y) w -= 0.01 * grad print ('\tgrad: ' , x, y, grad) l = loss(x, y) print ('progress:' , epoch, "w=" , w, "loss=" , l) print ('Predict (after training)' , 4 , forward(4 ))
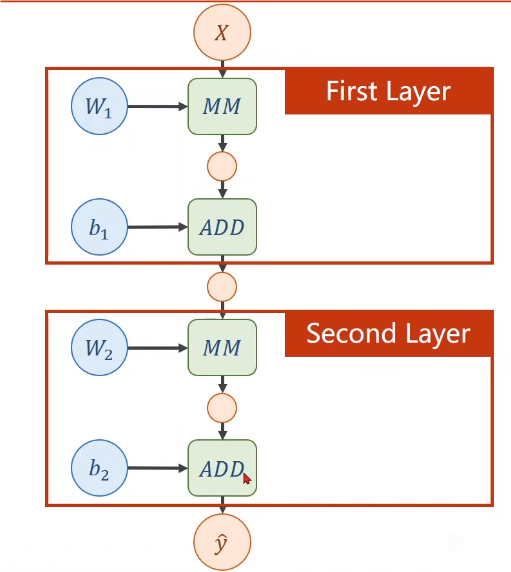
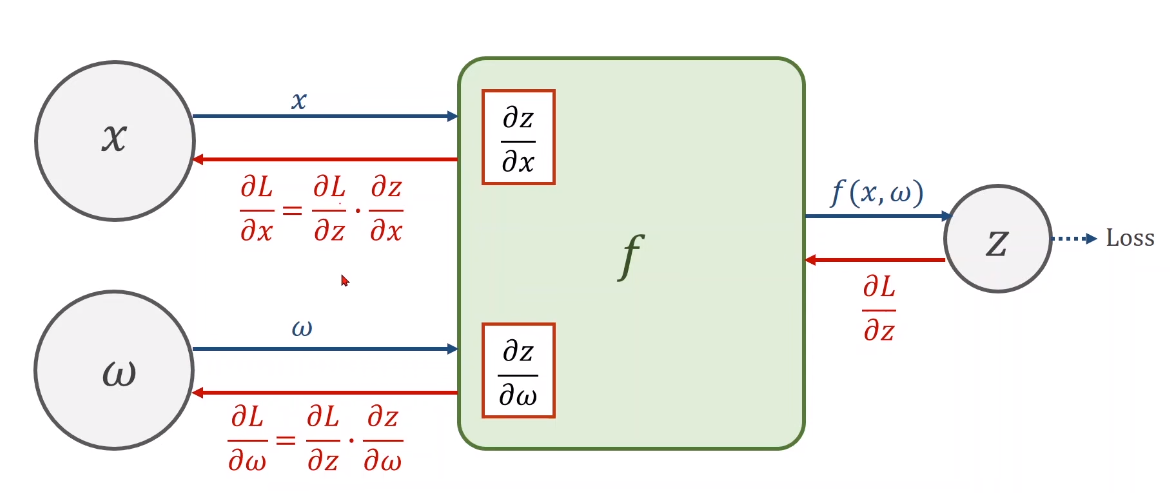
# 反向传播先将 x 以权重 w 进行预测得到y ^ \hat y y ^ 通过ω = ω − α ∂ l o s s ∂ ω \omega=\omega-\alpha\frac{\partial loss}{\partial\omega} ω = ω − α ∂ ω ∂ l o s s ω \omega ω y ^ = W 2 ( W 1 ⋅ X + b 1 ) + b 2 \hat{y}=W_2(W_1\cdot X+b_1)+b_2 y ^ = W 2 ( W 1 ⋅ X + b 1 ) + b 2 隐藏层 :W 1 ⋅ X + b 1 W_1 \cdot X+b_1 W 1 ⋅ X + b 1 激活函数 σ ( ) \sigma() σ ( ) 反向传播:反向传播 —— 更新参数ω \omega ω # Pytorch 讲解# Tensor——PyTorch 重要元素 保持元素 (Data:ω \omega ω ∂ l o s s ∂ ω \frac{\partial loss}{\partial\omega} ∂ ω ∂ l o s s # 代码实现
1 2 3 4 5 6 7 import torchx_data = [1.0 , 2.0 , 3.0 ] y_data = [2.0 , 4.0 , 6.0 ] w = torch.Tensor([1.0 ]) w.requires_grad = True
w.requires_grad = True :表示模型需要计算梯度。
1 2 3 4 5 6 def forward (x ): return x * w def loss (x, y ): y_pred = forward(x) return (y_pred - y) ** 2
w : 是一个 tensorforward : 计算y ^ \hat y y ^ loss :损失函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 print ("predict (before training)" , 4 , forward(4 ).item())for epoch in range (100 ): for x, y in zip (x_data, y_data): l = loss(x, y) l.backward() print ('\tgrad:' , x, y, w.grad.item()) w.data = w.data - 0.01 * w.grad.data w.grad.data.zero_() print ("progress:" , epoch, l.item()) print ("predict (after training)" , 4 , forward(4 ).item())
loss :计算损失函数l : 损失函数l.backward() : 计算链路上的所有需要的梯度,并且存到变量里面。w.data = w.data - 0.01 * w.grad.data : 因为 w 是一个 tensor ,为了计算具体的数值,需要操作到 w.grad.dataw.grad.data.zero_() :将权重里计算好的梯度等全部清零。# 用 pytorch 实现线性回归在 pytorch 中,如果计算y ^ = ω ⋅ x + b \hat y=\omega \cdot x+b y ^ = ω ⋅ x + b x x x 3 × 1 3×1 3 × 1 ω 和 b \omega 和 b ω 和 b 3 × 1 3×1 3 × 1
# torch.nn.Lineartorch.nn.Linear 类对输入数据应用线性变换。这种变换可以用以下方程表示:
y = A x + b y=Ax+b y = A x + b
# 参数in_features : 每个输入样本的特征数量(输入特征的维度)。out_features : 每个输出样本的特征数量(输出特征的维度)。bias : 如果设置为 False ,该层将不会学习一个加性的偏置。默认值是 True 。# 形状输入 : ( N , ∗ , in_features ) (N, *, \text{in\_features}) ( N , ∗ , in_features ) ∗ * ∗ ( N , in_features ) (N, \text{in\_features}) ( N , in_features ) N N N in_features \text{in\_features} in_features 输出 😒 (N, *, \text{out_features}),其中除了最后一维,其他维度与输入形状相同。对于形状为 ,其中除了最后一维,其他维度与输入形状相同。对于形状为 , 其 中 除 了 最 后 一 维 , 其 他 维 度 与 输 入 形 状 相 同 。 对 于 形 状 为 N N N out_features \text{out\_features} out_features # 变量weight : 模型中可学习的权重,其形状为 。bias : 模型中可学习的偏置,其形状为( out_features ) (\text{out\_features}) ( out_features ) 在一个简单的线性层中,输入特征通过一个学习到的权重矩阵和一个可选的偏置向量被转换为输出特征,这使得模型能够学习输入和输出之间的关系。这种变换在神经网络中对于回归和分类等任务是至关重要的。
# 自己设计可调用类
1 2 3 4 5 6 7 8 9 10 11 12 class sky : def __init__ (self ): pass def __call__ (self, *args, **kwargs ): pass def func (a,b,c,x,y ): pass func(1 ,2 ,4 ,3 ,x=3 ,y=5 )
*args 用于将不定数量的位置参数传递给函数。位置参数是指那些按顺序传递的参数。在函数内部, *args 是一个元组,包含了所有传递给函数的额外位置参数。 **kwargs 用于将不定数量的关键字参数传递给函数。关键字参数是指那些以 key=value 形式传递的参数。在函数内部, **kwargs 是一个字典,包含了所有传递给函数的额外关键字参数。 # 代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import torchimport torch.nn as nn x_data = torch.Tensor([[1.0 ], [2.0 ], [3.0 ]]) y_data = torch.Tensor([[2.0 ], [4.0 ], [6.0 ]]) class LinearModel (nn.Module): def __init__ (self ): super (LinearModel, self).__init__() self.linear = torch.nn.Linear(1 , 1 ) def forward (self, x ): y_pred = self.linear(x) return y_pred model = LinearModel() criterion = torch.nn.MSELoss(size_average=False ) optimizer = torch.optim.SGD(model.parameters(), lr=0.01 ) for epoch in range (100 ): y_pred = model(x_data) loss = criterion(y_pred, y_data) print (epoch, loss.item()) optimizer.zero_grad() loss.backward() optimizer.step() print ('w = ' , model.linear.weight.item())print ('b = ' , model.linear.bias.item())x_test = torch.Tensor([[4.0 ]]) y_test = model(x_test) print ('y_pred = ' , y_test.data)
nn :Neural Network
LinearModel() : 可以直接调用的线性模型
torch.nn.MSELoss(size_average=False) : 继承自 nn , size_average=False : 不求均值
torch.optim.SGD : 优化器,
model.parameters() 返回模型中所有需要优化的参数,这些参数将由优化器在训练过程中进行更新。
lr=0.01
loss = criterion(y_pred, y_data)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 常用优化器列表:
1 2 3 4 5 6 7 8 9 10 optimizers = [ optim.Adagrad, optim.Adam, optim.Adamax, optim.ASGD, optim.LBFGS, optim.RMSprop, optim.Rprop, optim.SGD ]
# 激活函数σ \sigma σ 一般情况下σ \sigma σ
# 逻辑斯特函数σ ( x ) = 1 1 + e − x \sigma(x)=\frac{1}{1+e^{-x}} σ ( x ) = 1 + e − x 1
# 误差函数(Error Function)e r f ( π 2 x ) \mathrm{erf}\left(\sqrt{\frac{\pi}{2}} x \right) e r f ( 2 π x )
定义 : erf(x) 是在概率、统计以及偏微分方程中广泛使用的特殊函数。用途 :主要用于正态分布中的积分计算。# 双曲正切函数t a n h ( x ) = e x − e − x e x + e − x tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}} t a n h ( x ) = e x + e − x e x − e − x
用途 :常用作神经网络中的激活函数。其输出范围为 [-1, 1],有助于将输入值压缩到有限范围内。# Gudermannian 函数2 π g d ( π 2 x ) \frac{2}{\pi} \mathrm{gd}\left(\frac{\pi}{2} x \right) π 2 g d ( 2 π x )
用途 :用于数学中的一些特殊变换,尽管在神经网络中不常见。# ArcSinh 激活函数的倒数形式x 1 + x 2 \frac{x}{\sqrt{1 + x^2}} 1 + x 2 x
# 归一化的反正切函数2 π arctan ( π 2 x ) \frac{2}{\pi} \arctan\left(\frac{\pi}{2} x \right) π 2 arctan ( 2 π x )
用途 :在神经网络中作为激活函数,输出范围为 [-1, 1]。# 软符号函数x 1 + ∣ x ∣ \frac{x}{1 + |x|} 1 + ∣ x ∣ x
用途 :用于神经网络中的激活函数,将输入值压缩到 [-1, 1] 范围内。# 逻辑斯特回归# minist 数据集
1 2 3 4 5 import torchvisiontrain_set = torchvision.datasets.MNIST(root='./dataset/mnist' , train=True , download=True ) test_set = torchvision.datasets.MNIST(root='./dataset/mnist' , train=False , download=True )
train_set 加载的是训练数据集( train=True )。test_set 加载的是测试数据集( train=False )。root 参数指定了数据集的存储路径。download=True 表示如果数据集不存在,则从互联网下载数据集。mnist 数据集: # CIFAR-10 数据集训练集提供了:50000 个样本 测试集提供了:10000 个样本 分为十个类 二分类问题:只有一和零的区别
# 损失函数l o s s = − ( y l o g y ^ + ( 1 − y ) l o g ( 1 − y ^ ) ) loss=-(ylog\hat y+(1-y)log(1-\hat y)) l o s s = − ( y l o g y ^ + ( 1 − y ) l o g ( 1 − y ^ ) )
# 代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import torchimport torch.nn.functional as Fx_data = torch.Tensor([[1.0 ], [2.0 ], [3.0 ]]) y_data = torch.Tensor([[0 ], [0 ], [1 ]]) class LogisticRegressionModel (torch.nn.Module): def __init__ (self ): super (LogisticRegressionModel, self).__init__() self.linear = torch.nn.Linear(1 , 1 ) def forward (self, x ): y_pred = F.sigmoid(self.linear(x)) return y_pred model = LogisticRegressionModel() criterion = torch.nn.BCELoss(size_average=False ) optimizer = torch.optim.SGD(model.parameters(), lr=0.01 ) for epoch in range (1000 ): y_pred = model(x_data) loss = criterion(y_pred, y_data) print (epoch, loss.item()) optimizer.zero_grad() loss.backward() optimizer.step()
criterion=torch.nn.BCELoss(size_average=False) :损失函数 - 交叉熵optimizer = torch.optim.SGD(model.parameters(), lr=0.01) : 采用 SGD 优化器