# 逻辑斯特回归
逻辑斯特回归(Logistic Regression)是一种广泛应用于分类问题的统计方法。尽管名字中带有 “回归” 一词,但逻辑斯特回归实际上是用于二分类问题的。
# 基本原理
逻辑斯特回归的基本思想是使用逻辑斯特函数(也称为 Sigmoid 函数)将线性回归模型的输出转换为介于 0 和 1 之间的概率,从而用于分类。
# 数学表达
线性模型: 首先,逻辑斯特回归使用线性回归模型来计算输入变量的线性组合:
z=wTx+b
其中,w 是权重向量,x 是输入特征向量,b 是偏置项
逻辑斯特函数: 然后,将线性组合的结果z 通过逻辑斯特函数转换为概率:
y^=σ(z)=1+e−z1
其中,σ(z) 是逻辑斯特函数,y^ 是预测的概率值,表示样本属于正类的概率
# 决策边界
逻辑斯特回归的输出是一个概率,通过设定一个阈值(通常为 0.5),将概率转换为二分类结果:
y^={10if σ(z)≥0.5if σ(z)<0.5
# 损失函数
为了训练逻辑斯特回归模型,使用了对数似然损失函数(Log-Likelihood Loss)或称为交叉熵损失(Cross-Entropy Loss):
J(w,b)=m1i=1∑mL(y^(i),y(i))=−m1i=1∑m(y(i)logy^(i)+(1−y(i))log(1−y^(i)))
其中,N 是样本数量,yi 是第i - 个样本的真实标签,y^i 是第i 个样本的预测概率。
# 梯度下降发训练
更新w:
w=w−αdwdJ(w)
# 学习率
在深度学习中,学习率(Learning Rate)是一个至关重要的超参数,它控制着模型权重更新的步长大小。在训练神经网络时,学习率决定了每次迭代时模型参数(如权重和偏置)的更新速度。具体来说,学习率影响着梯度下降算法中每一步调整的幅度。以下是学习率在深度学习中的具体意义:
# 学习率的求法和调整方法
确定和调整学习率是深度学习中一个关键的步骤,可以通过以下几种方法来选择和调整学习率:
固定学习率:
- 直接设定一个固定的学习率值,这是最简单的方法。常用的初始学习率范围在 0.01 到 0.0001 之间,具体取决于问题的复杂度和数据特性。
学习率调优:
- 网格搜索(Grid Search):在一组预定义的学习率值中进行搜索,选择表现最好的学习率。
- 随机搜索(Random Search):在一定范围内随机选择学习率值进行实验,找到较好的学习率。
自适应学习率方法:
学习率衰减(Learning Rate Decay)
:随着训练的进行,逐渐减小学习率。常见的衰减方法有:
- 时间衰减:学习率随着时间线性或指数衰减,如 α=α01+ktα=1+ktα0α=1+ktα0,其中 $\alpha_0 为初始学习率,k$ 为衰减率,t 为时间步。
- 分段常数衰减:在训练过程的不同阶段使用不同的固定学习率。
动量法(Momentum):引入动量项,使参数更新不仅依赖于当前的梯度,还依赖于之前更新的动量,平滑学习率的变化。
RMSProp 和 Adam:自适应方法,根据参数的历史梯度调整学习率。Adam 算法是 RMSProp 和动量法的结合,效果较好。
循环学习率(Cyclical Learning Rates):
- 让学习率在一定范围内周期性变化,可以帮助模型跳出局部最优解。
- 常用的方法有三角形策略(Triangular Policy)和余弦退火(Cosine Annealing)。
# 链式法则
要求drdjr是f函数的一个变量可以求drdj=dfdj∗drdf
# 梯度下降
# 逻辑回归梯度下降算法
初始化:
J=0,dw1=0,dw2=0,db=0
初始化代价函数J 和梯度dw1、dw2、db 为零。
循环遍历所有训练样本:
For i = 1 to m
对每个训练样本 $ (x^(i)}, y)$ 进行以下操作:
a. 计算线性组合 z 和激活值 a:
z(i)=wTx(i)+ba(i)=σ(z(i))=1+e−z(i)1
其中,$w 是权重向量,x^{(i)}是输入特征向量,b$ 是偏置。
b. 计算损失函数的梯度:
J+=−[y(i)loga(i)+(1−y(i))log(1−a(i))]dz(i)=a(i)−y(i)
- y: 训练样本的实际分类标签。对于二分类问题,y 通常取值为 0 或 1。
c. 累积梯度:
dw1+=x1(i)dz(i)dw2+=x2(i)dz(i)db+=dz(i)
平均梯度:
J/=mdw1/=m,dw2/=m,db/=m
将代价函数和梯度的累积值除以样本数 m,得到平均值。
更新参数:
w1=w1−αdw1w2=w2−αdw2b=b−αdb
其中,$\alpha $ 是学习率,用于控制每次参数更新的步长。
# 公式解释
线性组合z:
z(i)=wTx(i)+b
这是输入特征的线性组合加上偏置。
激活函数 σ(z):
a(i)=σ(z(i))=1+e−z(i)1
激活函数(sigmoid 函数)将线性组合 z 转换为概率值 a。
损失函数 J:
J=−m1i=1∑m[y(i)loga(i)+(1−y(i))log(1−a(i))]
交叉熵损失函数,用于衡量预测概率 a 与实际标签 y 之间的差距。
** 梯度 **dw1,dw2,db:
dw1=∂w1∂J,dw2=∂w2∂J,db=∂b∂J
这是损失函数对权重和偏置的导数,用于参数更新。
通过上述步骤,我们可以逐步调整模型参数 w 和 b,使得损失函数 J 最小化,从而训练出一个良好的逻辑回归模型。图中还提到了一些向量化的方法,可以加速计算过程,特别是在处理大规模数据集时。
# 向量化
在非向量化的情况下,逻辑斯特回归可以表示为:
z=ωTx+b
计算z 的过程可以用一个循环来实现:
1
2
3
4
| z = 0
for i in range(n_x):
z += w[i] * x[i]
z += b
|
这里的循环逐个元素地进行乘法和加法操作,效率较低。
在向量化的情况下,计算z 可以利用 NumPy 的 dot 函数进行向量点击运算,具体表示为:
z=np.dot(ω,x)+b
通过向量化操作,可以将多个标量运算合并成单个向量运算,从而显著提升计算效率。向量化的代码如下:
# numpy 操作
np.dot(w, x) :点积u=np.exp(v) :全成指数a→eanp.abs :求绝对值np.maximum :求最大值np.log :求对数
# 逻辑斯特向量化
- 线性组合:z(i)=wTx(i)+b
- 激活函数:a(i)=σ(z(i))
代码向量化:
# 反向传播向量化
- 误差计算:dz(i)=a(i)−y(i),其中a(i)是模型预测的输出,y(i)是真实标签
- 将向量化误差表示为1×m 的向量,dZ=[dz(1) dz(2) ⋯dz(m)]
- 计算:A: 模型对所有样本的预测值、Y: 所有样本的真实标签.
A=[a(1)a(2)⋯a(m)]
Y=\begin{bmatrix}y^{(1)}&y^{(2)}&\cdots&y^{(m)}\end - 误差向量化表示为:dZ=A−Y
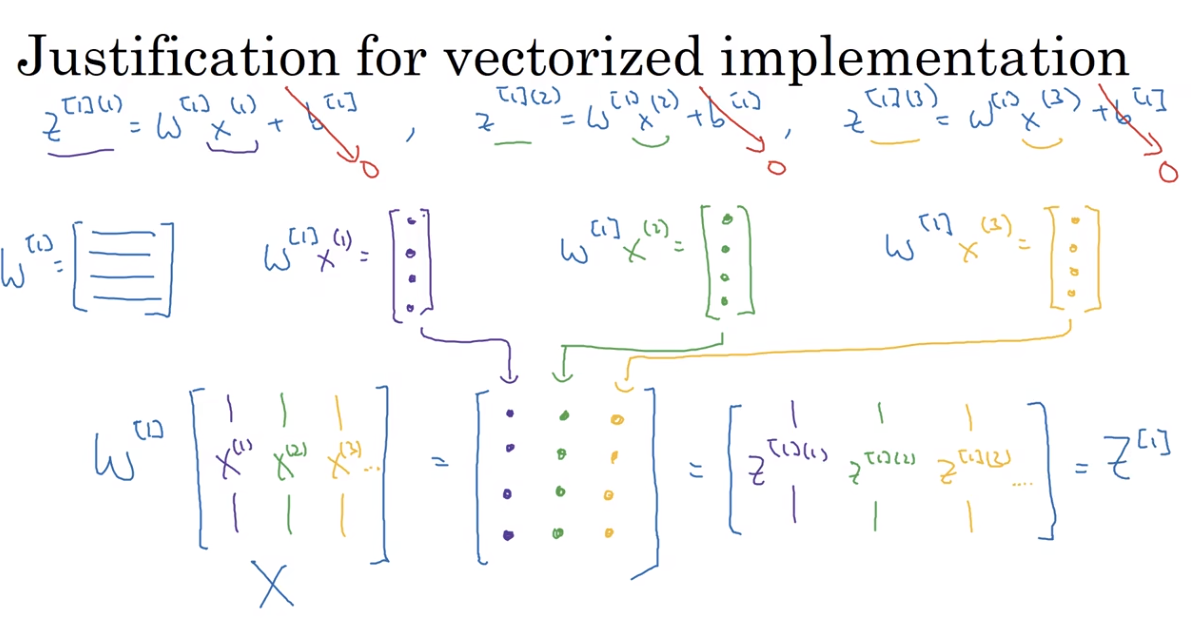
- 计算权重梯度:dw=0 → dw+=x(i)∗dz(i) → dw=m1∑i=1mx(i)⋅dz(i)
dw=m1XdZT - 计算偏执梯度:db=0 → db+=dz(i) → db=m1∑i=1mdz(i)
db=m1np.sum(dZ)
# 神经网络
# a_i^
- 不同的上表方括号表示神经网络里不同的值
- l: 表示神经网络的第l 层
- i:表示层中的第i 个节点
# 神经网络
![image.png]()
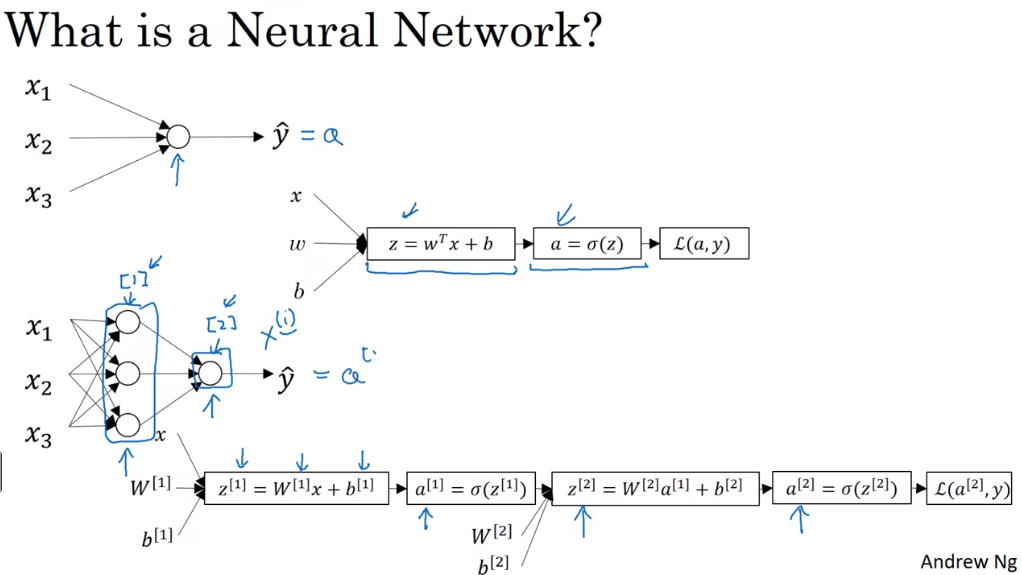
# 单个神经元
单层神经元如上图,输入向量为x=[x1,x2,x3],输出为y^
# 计算过程
线性组合:
z=wTx+b
- wT 表示权重向量 w 的转置
- b 是偏置
激活函数:
a=σ(z)
- $\sigma $ 是激活函数,将线性组合的结果 z 转换为激活值 a
输出:
y^=a
# 多层神经网络
上图左下角展示了一个简单的三层神经网络,输入向量x=[x1,x2,x3],通过一层隐藏层到达输出层。
# 计算过程
输入层到隐藏层:
输入向量x 通过权重矩阵W[1] 和偏置向量b[1] 进行线性组合
z[1]=W[1]x+b[1]
线性组合的结果z[1] 通过激活函数σ 得到隐藏层的激活值哦a^
a[1]=σ(z[1])
隐藏层到输出层:
隐藏层的激活值a[1] 通过权重矩阵W[2] 和偏置向量b[2] 进行线性组合
z[2]=W[2]a[1]+b[2]
线性组合的结果z[2] 通过激活函数σ 得到输出层的激活值a^
a[2]=σ(z[2])
损失函数:
- 输出层的激活值a[2] 通过损失函数L(a[2],y) 与真实标签y 进行比较,计算损失:
L(a[2],y)
# 伪代码实现
Given input x:
z[1]=W[1]+b[1]→a[1]=σ(z[1])z[2]=W[2]a[1]+b[2]→a[2]=σ(z[2])
# 计算神经网络输出
![QQ_1721360320879.png]()
# 多层神经网络
![QQ_1721360642812.png]()
# 将多个样本向量化
公式:
for i = 1 to m: z[1](i)=W[1]x(i)+b[1] a[1](i)=σ(z[1](i)) z[2](i)=W[2]a[1](i)+b[2] a[2](i)=σ(z[2](i))
![QQ_1721369470589.png]()
# 神经网络图
![QQ_1721369714169.png]()
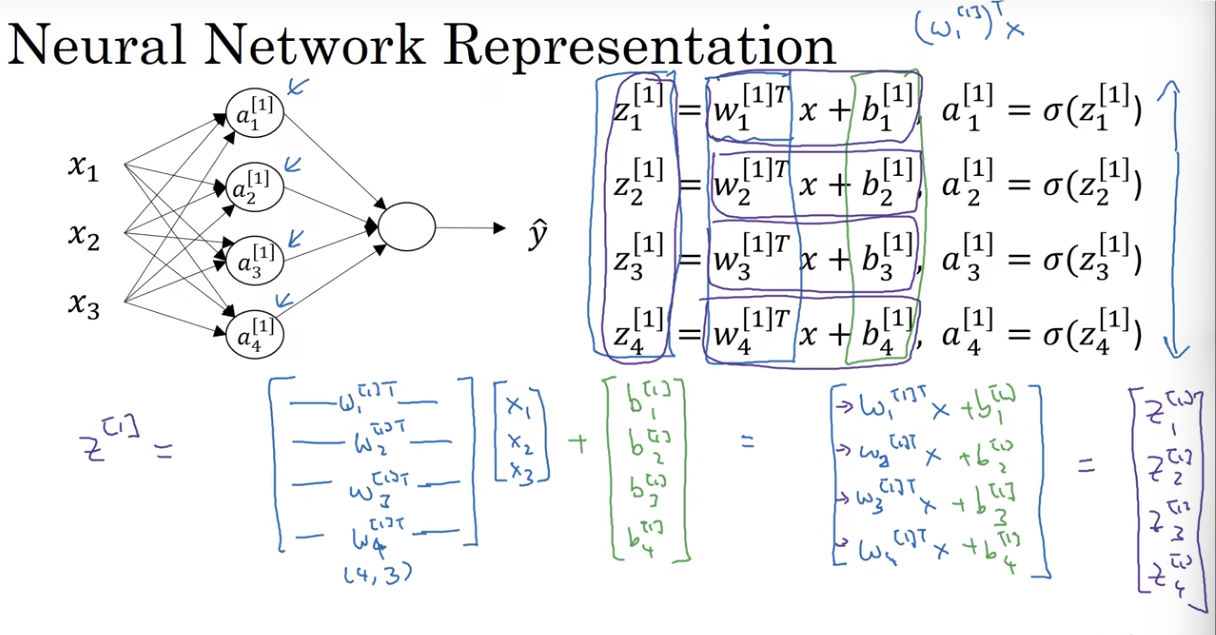
图片左上角展示了一个简单的神经网络结构,输入层有三个节点 $ x_1, x_2, x_3,经过一个隐藏层,输出一个预测值 \hat {y}$。
右上角的代码片段 for i = 1 to m: 表示我们对 m 个样本逐个进行处理。
- z[1](i)=W[1]x(i)+b[1] 表示第i 个样本在第一层的线性组合
- a[1](i)=σ(z[1](i)) 表示通过激活函数σ 计算出第i 个样本在第一层的激活值
- z[2](i)=W[2]a[1](i)+b[2] 表示第i 个样本在第二层的线性组合
- a[2](i)=σ(z[2](i)) 表示通过激活函数σ 计算出第i 个样本在第二层的激活值
输入矩阵 X:
- 每一列表示一个样本的数据,每一行表示一个特征
- X=[x(1),x(2),…,x(m)],其中 x(i) 表示第i 个样本的输入向量
向量化处理:
矩阵 W[1] 再加上偏置 b[1]。⋅A[1]=σ(Z[1]) 表示对线性组合结果应用激活函数 σ。⋅Z[2]=W[2]A[1]+b[2] 表示将第一层的激活值矩阵 A[1] 乘以权重矩阵 W[2] 再加上偏置 b[2]。A[2]=σ(Z[2]) 表示对′,↓,层的线性组合结果应用激活函数 σ。
第一层激活矩阵:
矩阵 A[1] 包含了所有样本在第一层的激活值 每一列表示一个样本的激活值,每一行表示一个神经元的输出。A[1]=[a[1](1),a[1](2),…,a[1](m)], 其中 a[1](i) 表示第 i 个样本在第一层的激活向量。
# 激活函数
# σ函数
σ=1+e−x1
# $ tanh$ 函数
tanh(x)=ex+e−xex−e−x
# 传播
反向传播(Backpropagation)是训练神经网络的核心算法之一,通过计算损失函数对每个参数的梯度,指导模型参数的更新。以下是反向传播算法的详细介绍,包括其基本原理、数学推导以及在神经网络中的应用。
# 基本原理
反向传播算法的基本思想是通过链式法则(Chain Rule),从输出层开始,逐层向后计算每个参数对损失函数的梯度。这个过程包括两个主要步骤:
# 前向传播
计算神经网络的输出 —— 前向传播是指将输入数据通过神经网络层层传递,直到得到最终的输出。假设有一个简单的三层神经网络(输入层、隐藏层、输出层),其计算过程如下:
激活函数:
a=σ(z)=1+e−z1
输出层误差:
dZ=y^−y=a−y
激活值a 对损失函数的偏导数:
J+=−[y(i)loga(i)+(1−y(i))log(1−a(i))]dL=∂a∂L=−ay+1−a1−y
线性组合z 的梯度:
dZ=dL⋅σ′(z)∙σ′(z)=σ(z)(1−σ(z)) 是 sigmoid 函数的导数。∙因为 a=σ(z),所以 dZ=a−y 已经考虑了这部分。
输入层到隐藏层:
z(1)=W(1)x+b(1)a(1)=σ(z(1))
其中,W(1) 是输入层到隐藏层的权重矩阵,b(1) 是偏置,σ 是激活函数
隐藏层到输出层:
z(2)=W(2)a(1)+b(2)a(2)=σ(z(2))
其中,W(2) 是隐藏层到输出层的权重矩阵,b(2) 是偏置
输出层:
y=a(2)
例子:
- 计算函数f 的输出z:
z=f(x,y)
# 反向传播
反向传播的目的是计算损失函数L 对每个参数的梯度。这个过程包括以下步骤:
计算输出层的误差:
δ(2)=∂z(2)∂L=∂a(2)∂L⋅σ′(z(2))
其中,δ(2) 是输出层的误差,σ′(z(2)) 是激活函数的导数
计算隐藏层的误差:
δ(1)=∂z(1)∂L=(W(2))Tδ(2)⋅σ′(z(1))
其中,δ(1) 是隐藏层的误差
计算梯度:
对权重的梯度:
∂W(2)∂L=δ(2)(a(1))T∂W(1)∂L=δ(1)xT
对偏置的梯度:
∂b(2)∂L=δ(2)∂b(1)∂L=δ(1)
- 这个公式表明输出层的偏置梯度就是输出层的误差。
- 这个公式表明隐藏层的偏置梯度就是隐藏层的误差
从损失函数L 对输出z 的梯度楷书:
∂z∂L
计算局部梯度∂x∂z 和\frac{\partial z}
通过链式法则,计算损失函数L 对输入x 和y 的梯度:
∂x∂L=∂z∂L⋅∂x∂z∂y∂L=∂z∂L⋅∂y∂z
# 梯度下降法的基本算法
# 参数定义
神经网络层数包括权重W 和偏置b,其中:
- W[1] 和b[1] 是第
1 层的权重和偏置 - W[2] 和b[2] 是第
2 层的权重和偏置
# 成本函数
成本函数J 定义如下:
J(W[1],b[1],W[2],b[2],…)=m1i=1∑mL(y^(i),y(i))
其中:
- m 是训练样本的数量
- L 是损失函数(例如,均方误差或交叉熵)
- y^ 是预测值
- y 是真实值
# 梯度下降算法
- 计算预测值y^
- 计算梯度:
- 对权重W:dW[l]=∂W[l]∂J
- 对偏置b:db[i]=∂b[l]∂J
- 更新参数:
- W[l]:=W[l]−α∂W[l]∂J
- b[l]:=b[l]−α∂b[l]∂J
- 其中α 是学习率
# 反向传播代码实现
![QQ_1721474062767.png]()
# Question:为什么偏置的梯度推导代码如上?
假设我们已经计算出第l层的线性组合Z[l] 和激活值 A[l]:Z[l]=W[l]A[l−1]+b[l]A[l]=g[l](Z[l])现在,我们需要计算 dW[l]。根据链式法则:dW[l]=∂W[l]∂J=∂Z[l]∂J⋅∂W[l]∂Z[l]我们知道:∂W[l]∂Z[l]=A[l−1]T因此,我们得到:dW[l]=dZ[l]⋅A[l−1]T由于我们是在所有样本上计算平均值,所以:dW[l]=m1i=1∑mdZ[l](i)⋅A[l−1](i)T在矩阵形式下,所有样本的和可以表示为矩阵乘法:dW[l]=m1dZ[l]A[l−1]T总结这就是为什么:∂W[l]∂J=dW[l]=m1dZ[l]A[l−1]T
# Question: 为什么∂W[l]∂Z[l]=A[l−1]T?
首先观察一个关键公式:
Z[l]=W[l]A[l−1]+b[l]
![image.png]()
# 随机初始化
# 为什么权重初始化不能为零
- 如果将所有权重初始化为零,那么每一层的所有神经元将产生相同的输出,导致反向传播时的梯度对称。这种对称性意味着每一层的所有神经元将以相同的方式更新,从而阻止网络有效地学习。
- a=Wx+b, 当权重W[1]和W[2] 初始化为零时,激活值a1[1]和a1[2] 相同
- 梯度ΔW 也是对称的,意味着\Delta W=\begin{bmatrix}u&u\\v&v\end
- 由权重更新规则,W[l]=W[l]−αΔW(其中 α 是学习率),若权重初始化为零,则不会打破对称性
计算规则:
ΔW=∂W∂L
1. 计算损失函数对 Z[2] 的偏导数:dZ[2]=A[2]−Y2.用u表示误差:dZ[2]=u
![dce2ce1cce49d3bdc4659eea6e157db4.png]()
# 如何随机初始化权重
在训练神经网络时,正确初始化权重对于有效训练非常重要。随机初始化权重可以避免神经元在每一层的输出相同,从而打破对称性,提高网络的学习能力。
# 网络结构
- 输入层有两个输入x1 和x2
- 隐藏层有两个神经元a1[1] 和a_2^
- 输出层有一个神经元a_1^
# 权重和偏置初始化
隐藏层权重W[1] 随机初始化,可以采用正态分布:
W[1]=np.random.randn(2,2)×0.01
这段代码的含义是生成一个 2×2 的矩阵,矩阵中的每个元素都是从标准正态分布(均值为 0,标准差为 1)中随机抽取的数,然后将这些数乘以 0.01。最终结果是一个 2×2 的矩阵,其中每个元素都是一个很小的随机数。
将隐藏层偏置b[1] 初始化为零:
b[1]=np.zeros((2,1))
再将输出层权重W[2] 和偏置b[2] 初始化为随机值和零:
W[2]b[2]=...=0