# 综述
# 1. 研究背景
- 移动社交网络的快速发展促进了人们的社会交往,但也导致了网络欺诈行为的增加。这些欺诈行为给个人和社会带来了巨大的经济损失。
- 检测欺诈用户的常用数据是通话记录(CDR),但这些数据存在严重的不平衡性,这会影响基于 GNN 的欺诈检测模型的效果。
# 2. 问题定义
- 图不平衡问题:图中正样本和负样本数量不平衡,特别是在社交网络欺诈检测中,欺诈用户仅占所有用户的一小部分。这种不平衡会影响模型的判断和效果。
- 挑战:主要有两个挑战 ——1) 正节点周围负邻居过多,影响 GNN 的聚合效果;2) 正节点在所有节点中的比例过低,模型难以学习到有效的模式。
# 3. 方法介绍
# 4. 实验和结果
- 实验数据集:使用了两个不平衡的电信欺诈检测数据集(四川数据集和 BUPT 数据集)。
- 实验结果:CS-GNN 在这两个数据集上的表现优于其他基准方法,特别是在处理图不平衡问题上展现出了显著优势。
# 5. 模型性能分析
- 不平衡率影响:随着数据集中不平衡率的变化,CS-GNN 依然保持了较好的表现,证明了该方法在处理不平衡图时的鲁棒性。
- 消融实验:通过去除邻居采样和成本敏感学习模块,验证了这两个模块对最终模型效果的重要性。
# 6. 总结
- 该研究提出了一种有效解决图不平衡问题的 CS-GNN 模型,通过强化学习和成本敏感学习的结合,显著提高了在移动社交网络欺诈检测中的表现。
# 预备工作
# 符号表
![image.png]()
# 图失衡定义
在一组图节点中,设有 K 个类别 C1,C2,…,CK. 其中 ∣Ci∣ 表示第 i 类的样本数量。图不平衡问题是指这些类别中的样本数量存在显著差异。
为了量化图的不平衡程度,文中引入了一个不平衡率IR,其定义如下:
IR=maxi(∣Ci∣)mini(∣Ci∣)
取值范围: IR 的取值范围为 [0, 1]。如果 IR<1,意味着图是不平衡的(即某些类别的样本数明显少于其他类别)。当IR=1 时,图是平衡的(即所有类别的样本数相等)。
# 成本敏感学习(Cost Sensitive Learning)
- 成本敏感学习 是一种训练分类器的方法,通过为不同类别样本的错误分类赋予不同的惩罚来进行学习。与传统的尽可能减少错误分类率的方法不同,成本敏感学习侧重于在分类决策中引入不同类型的错误分类成本,以减少总体的错误分类成本。
# 成本矩阵C
成本敏感学习的核心在于定义一个错误分类成本矩阵 $ C$。这个矩阵的每个元素 Cij 表示将类别 $i $ 的样本错误分类为类别 j 的惩罚成本。通常情况下,类别数为K,则成本矩阵 $C 的维度为 K \times K$。
矩阵形式:
C=⎣⎢⎢⎢⎢⎡C10C20⋮CK0C11C21⋮CK1⋯⋯⋱⋯C1KC2K⋮CKK⎦⎥⎥⎥⎥⎤
Cij 的值越大,表示该错误分类的损失越大
# 基于 GNN 的社交网络欺诈
构建一个社交行为图G=(V,X,A,E,Y)。其中:∙V={v1,v2,v3,...vN} 表示节点集合,即订阅者的集合。∙X=x1,X2,...,xN是订阅者原始行为的特征集合。其中xi∈R是订阅者vi的行为特征向量。这些特征向量组成一个矩阵,即图G的特征矩阵X∙A∈RN×N 是图 G 的邻接矩阵,其中 ai,j=1 表示节点 i 和节点 j 之间存在边,如果没有边则 ai,j=0。∙E代表的是图中的边集合∙Y={y1,y2,...,yn} 是标签的集合。
# GNN 的中间层传递公式
对于给定的移动社交网络,GNN 可以用于节点嵌入学习。GNN 中层间的传递公式可以形式化地表示为:
hv(l)=σ(hv(l−1)⊕Agg{hv′(l−1):(v,v′)∈E})′:′约束条件,表示只有满足后面条件的节点才会被考虑其中:∙hv(l) 表示第 l 层中节点 v 的嵌入,hv(0)=xv 是节点 v 的初始特征。∙v′ 是节点 v 的邻居节点。Agg()是用于邻居特征聚合的消息聚合函数,比如平均聚合(meanaggregation)、池化聚合(pooling aggregation)、注意力聚合(attention aggregation)等。σ 是激活函数。⊕ 表示特征的连接或求和操作。
# 模型建立
![image.png]()
# 整体概述
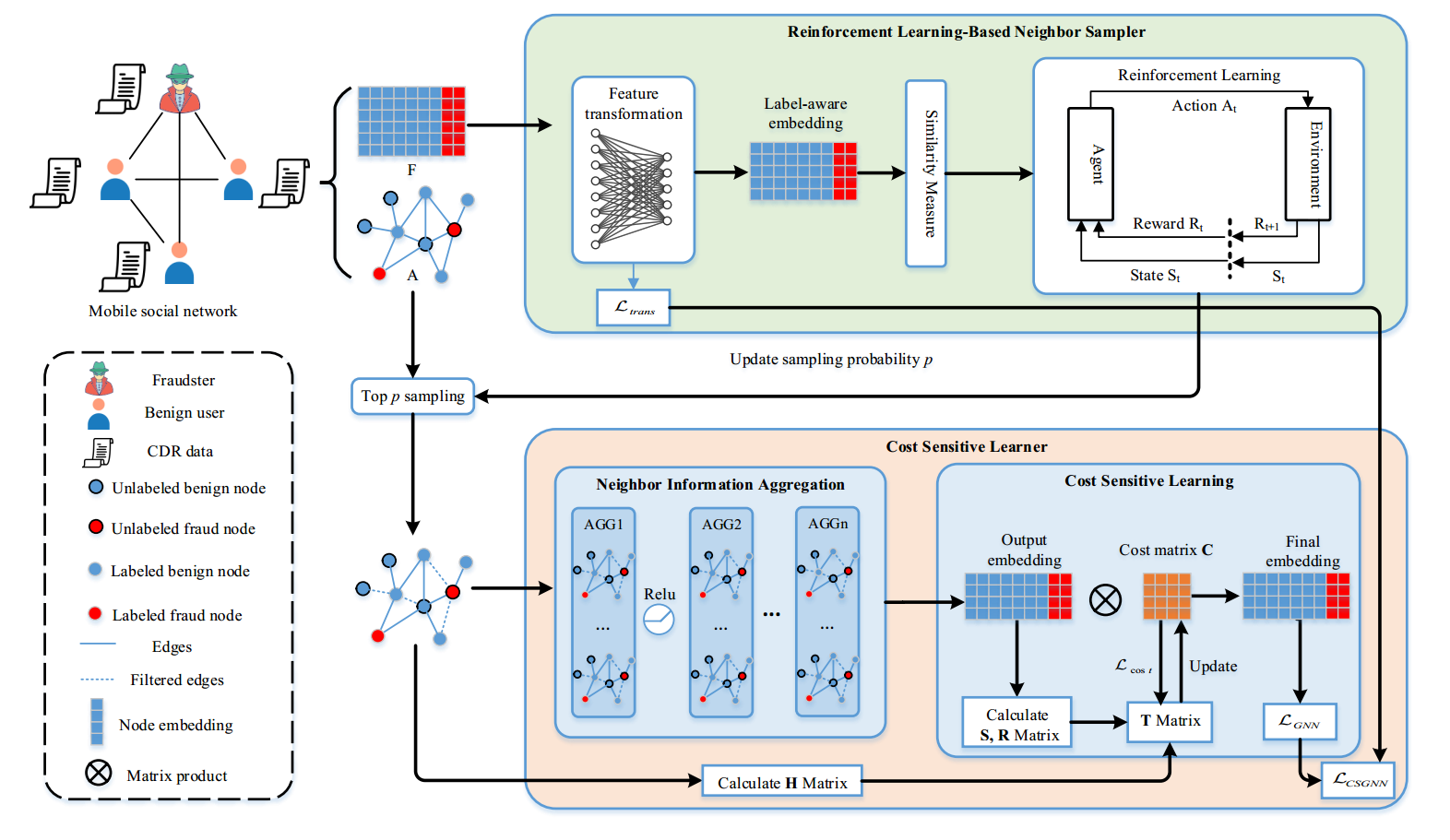
# 1. 整体流程概述(Pipeline Overview)
- 图的输入:首先,将一个图输入到基于强化学习的邻居采样器中。这个图代表了移动社交网络,其中节点代表用户,边代表用户之间的联系。
# 2. 基于强化学习的邻居采样器(Reinforcement Learning-Based Neighbor Sampler)
- 特征转换(Feature transformation):通过特征转换将原始输入特征转换为适合 GNN 处理的特征向量。
- 标签感知嵌入(Label-aware embedding):根据标签信息生成嵌入表示。
- 相似度度量(Similarity Measure):计算节点之间的相似度。
- 强化学习模块(Reinforcement Learning Module):使用强化学习方法动态调整邻居的采样概率 $ p$,根据相似度排序后,进行 top-p 采样,选择最相似的邻居节点。
# 3. 成本敏感学习器(Cost Sensitive Learner)
- 邻居信息聚合(Neighbor Information Aggregation):在 GNN 中使用信息聚合函数(如平均聚合、池化聚合等)对节点的邻居信息进行聚合,以获得节点的嵌入表示。
- 成本敏感学习(Cost Sensitive Learning): 通过成本敏感矩阵 $ C$ 对节点嵌入进行转换,以考虑不同类别之间的分类成本。
- 输出嵌入(Output embedding):通过成本敏感学习得到节点的最终嵌入表示。
- 更新矩阵(T Matrix):根据优化目标 Lcost 更新成本敏感矩阵。
- 最终嵌入(Final embedding):最终输出的节点嵌入用于分类。
# 4. 最终分类
- 在得到成本敏感的节点嵌入表示后,模型使用这些嵌入表示进行最终的分类。
# 节点特征转换
根据中心节点和相邻节点的相似性对相邻节点进行采样
使用全连接网络(FCN) 作为节点特征转换器,将原始节点v 的特征xv 转换为嵌入表示hv
转换公式为:
hv=σ(Wxv)
其中,σ 是 ReLU 函数,W 是需要学习的网络权重矩阵
欧式距离计算节点v 和邻居节点v′ 直接的距离,公式为:
D(v,v′)=∣∣hv−hv′∣∣2∥hv−hv′∥2=i∑(hv,i−hv′,i)2其中 hv 和 hv′ 分别是节点 v 和 v′ 的特征向量,hv,i 和 hv′,i 是这些向量的第 i 个分量。
** 相似度计算:** 根据计算得到的距离D(v,v′),可以得到节点v 与其邻居节点v′ 的相似度S(v,,v′), 公式为:
S(v,v′)=1−D(v,v′)
** 目标优化:** 使用交叉熵损失函数作为全连接层的优化目标:
Ltrans=−v∈V∑yvlog(hv)
yv 是节点v 的标签,log(hv) 是节点嵌入的对数
# 节点邻居采样
# 状态
每个 epoch 中训练集节点的平均相似度:
G(S)(e)=∣E(e)∣∑v,v′∈TrainS(v,v′)
E(e) 表示第e 个 epoch 边的集合,S(v,v′) 是节点v 和其邻居节点v′ 的相似度
定义了两种状态:
∙s1:当∙s2:前epoch的平均节点相似度高于前一个epoch,即G(S)(e−1)<G(S)(e)。前epoch的平均节点相似度低于或等于前一个epoch,即G(S)(e−1)≥G(S)(e)。
# 动作
强化学习模块的目标是学习最优的邻居过滤阈值 $ p$。
动作空间A 定义了两个动作:
- a1: 增加采样概率p 和一个固定步长τ
- a2: 减少采样概率p 和一个固定步长τ
根据当前状态s,通过映射关系π 选择动作:
a=π(s)={p+τ,p−τ,ifs=s2ifs=s1
# 奖励机制
奖励函数f(p,a)(e) 用于评估每个 epoch 的动作效果:
f(p,a)(e)={+1,−1,ifG(S)(e−1)≤G(S)(e)ifG(S)(e−1)>G(S)(e)
如果当前 epoch 的平均距离(即相似度的负数)比前一个 epoch 更小(表示相似度更高),则给予正奖励 +1,反之则给予负奖励 -1。
奖励机制确保采样概率 $ p$ 的调整能够逐步收敛到一个最优值,从而在每个节点的邻居中选择最合适的邻居集合。
# 终止条件
终止条件是为了节省计算资源,当模型在最后 15 个 epoch 中收敛时,认为最优阈值p(l) 已经找到,此时终止强化学习模块。
终止的具体条件是:如果在最后 15 个 epoch 中,奖励函数的和满足以下条件:
∣∣∣∣∣∣e−15∑ef(p,a)(e)∣∣∣∣∣∣≤2
则认为模型已经收敛并且停止更新
# 敏感学习
邻居采样的影响:在执行邻居采样之后,新生成的图可以显著减少正节点的负邻居节点数量。这样做的目的是减少不相关的或负面的影响,从而提高模型的准确性。
极端情况的风险:尽管减少负邻居节点数量有助于提高模型性能,但如果过度减少,甚至完全平衡图中的正负样本数量,反而会对模型产生不利影响。具体来说,过多的负节点被过滤掉可能导致大量有效数据丢失。这种数据丢失会削弱模型的学习能力,从而降低模型的整体表现
成本敏感学习器的引入:为了应对上述问题,设计了一种成本敏感学习器,用于在邻居采样后训练 GNN 的输出嵌入。该学习器旨在平衡样本不均衡对模型的影响。
# 模块组成
GNN 节点嵌入学习模块:负责从图中学习节点的嵌入表示。
成本敏感模块:在嵌入学习的基础上,结合不同类别的分类成本,调整模型的决策过程,从而提高模型在不均衡数据集上的表现。
# 邻居信息聚合
注意力机制与权重参数:许多现有的 GNN 模型倾向于使用注意力机制或设计加权参数来进行消息聚合,以提高模型的性能。这些方法通过在消息传递和聚合过程中对邻居节点施加不同的权重来优化节点的表示。
计算成本问题:然而,当已经为每个节点选择了最相似的邻居后,使用注意力系数或加权参数在信息聚合中可能意义不大,并且会显著增加计算成本
平均聚合器(Mean Aggregator):为了在节省计算成本的同时保留领域中的重要信息,作者选择了一种简单且高效的聚合器 ——GraphSAGE 模型中的平均聚合器(Mean Aggregator)。
- 与注意力机制相比,平均聚合器大大降低了模型的复杂性,同时仍然能够有效地进行信息聚合。
# 具体实现
hv(l)=σ(W⋅AGG({hv(l−1)}∪{hv′(l−1),∀v′∈N(v)}))⋅这里,σ是激活函数,W是需要学习的权重矩阵。⋅N(v) 是节点 v 的邻居节点集合。聚合函数AGG使用的是平均聚合(MEAN),即对节点及其邻居的嵌入进行平均。
AGG({hv(l−1)}∪{hv′(l−1),∀v′∈N(v)})=∣N(v)∣+11v′∈{v}∪N(v)∑hv′(l−1)
平均操作:MEAN () 函数表示对集合中节点的嵌入取平均值。
下游任务:将节点的嵌入 hv(l) 作为最后一层 GNN 输出的表示,用于执行后续的下游任务(例如节点分类或边预测等)。
# 降低成本的学习方案
不平衡图中的问题:在处理不平衡图时,直接使用节点嵌入进行下游任务(如节点分类)通常效果不佳。为了解决这个问题,作者引入了成本敏感学习。
基本思路:通过对节点嵌入应用成本敏感矩阵 $ C,来调整每个节点 v 属于不同类别 k 的概率 p_k (v)$。具体算法如下:
pk(v)=Softmax(C[v,k]⋅zv[k])=∑k′Cv,k′exp(zv[k′])Cv,kexp(zv[k])
- C[v,k] 是成本矩阵C 中的元素,表示将节点v 分配到类别k 的成本
- zv[k] 是节点v 的最终嵌入中第k 维的值
# 成本矩阵的挑战
挑战:主要挑战在于如何合理确定成本矩阵 $ C$ 中每个元素的值。过去的工作通常根据专家经验或数据中的不平衡率来设定这些值,但这种方法不能自适应地应对数据集的变化。
解决方案:为了解决这个问题,作者设计了一种可自动优化的成本敏感矩阵算法。
# 成本矩阵的优化
数据分布矩阵(H Matrix):数据分布矩阵 $ H$ 考虑了训练集中不同类别数据的分布情况。对于多数类样本,应该分配较低的成本,而对于少数类样本,应该分配较高的成本。
数据分布直方图矩阵 H(i,j) 定义如下:H(i,j)={max(hi,hj),hi,if i=j,(i,j)∈Cif i=j,i∈C其中 hi 表示类别 i 的直方图分布。
散布矩阵(S Matrix):散布矩阵 $ S $ 用于衡量同类样本的嵌入在高维空间中的聚集程度。样本同类的嵌入应当距离较小,而不同类样本的嵌入应当距离较大。
∙ 类内散布矩阵 SW 定义为:SW=i=1∑K(Ni1j=1∑Ni(xi,j−mi)(xi,j−mi)⊤)∙ 类间散布矩阵 SB 定义为:SB=i=1∑K(mi−m)(mi−m)⊤其中mi是类别i的样本均值,m是所有类别样本的总均值。∙ 最终的散布矩阵S定义为:S=SBSW
归一化混淆矩阵(R Matrix):归一化混淆矩阵 $ R$ 用于捕捉分类结果中的误分类信息。当前 epoch 中误分类的样本应在下一 epoch 中获得更大的权重。
R(i,j)=∣V∣∣∣∣∣∣{v∣kargmaxpk(v)=j,yv=i}∣∣∣∣∣
# 最终优化目标
将上述三种矩阵 $ H、S、R 结合起来,定义了一个成本矩阵的优化目标 T$:
T=β⋅H∘S∘R其中 β 是超参数,∘表示Hadamard乘积(元素乘积)。
最终的成本函数 Lcost(C,T) 用于衡量训练成本矩阵 C 与目标 T 之间的差异:Lcost(C,T)=∣∣T−C∣∣22+Eval(θ,C)其中 Eval 是验证误差。
# 成本敏感学习初始化
初始化方法的局限性:传统的神经网络权重初始化方法,如 Xavier 初始化、Kaiming 初始化和随机初始化,通常适用于神经网络的大量参数。然而,这些方法在成本敏感矩阵 $C 上的应用效果不佳,因为 C 的维度通常很小(K \times K$),无法展示随机初始化的有效性。此外,这些方法也无法捕捉成本敏感学习的目标,即在模型中对少数类样本施加正确的成本影响。
# 从不平衡率IR 出发
为了克服上述问题,作者提出了基于样本不平衡率(IR)的初始值设定方法。具体地,考虑到 IR 的反比,使用其对数变换来初始化成本矩阵 $ C$ 中的每个元素:
Cij=log(IR1)=log(∣Ci∣∣Cj∣+1)其中,∣Ci∣ 和 ∣Cj∣ 分别表示类别 i 和类别 j 的样本数量。这种方法能够将有偏的成本值转换为一个无偏的正态分布。
# 成本矩阵优化
优化目标:在初始化成本矩阵后,作者定义了一个成本函数Lcost(C,T),并在每个 epoch 中通过一定的学习速率对成本矩阵 $ C$ 进行优化。优化目标是找到一个最优的成本矩阵 C∗,使得:
C∗=argCminLcost(C,T)
梯度下降法:为了解决上述优化问题,作者使用了梯度下降(Gradient Descent, GD)算法来计算每一步的更新方向。具体计算公式如下:
∇Lcost(C,T)=∇(va−vb)(va−vb)T=(va−vb)JvbT=−(va−vb)1T
其中,va 和 $ \mathbf {v}_b$ 是成本矩阵 $ C 和目标矩阵 T的向量化表示,\mathbf {J}$ 是 Jacobi 矩阵。
![image.png]()
# 成本敏感图神经网络算法及流程
# 算法损失函数定义
GNN 的交叉熵损失(CE loss):
在给定的欺诈检测图 $ G和节点集合 V_{\text {train}}$ 的情况下,GNN 的交叉熵损失函数定义为:
LGNN=−v∈V∑yvlog(pv)
其中yv 是节点 $ v的真实标签,p_v是节点 v$ 的预测概率。
CSGNN 的损失函数:
CSGNN 的总损失函数结合了 GNN 的交叉熵损失和节点特征变换的损失函数:
LCSGNN=LGNN+λLtransLtrans=−v∈V∑yvlog(hv)
# 算法流程
![image.png]()
算法的整体流程如下:
![image.png]()
# 输入:
- 一个无向图,其中包含节点特征和标签,记为G=(V,X,A,E,Y)
- 节点类别的数量K。
- 图神经网络的层数 $ L 和训练周期数 E$。
# 输出:
- 节点v∈Vtrain 的向量表示 pv。
# 初始化:
- 根据公式Cij=log1p(IR1)=log(∣Ci∣∣Cj∣+1),为训练集Vtrain 中的所有节点初始化成本矩阵 C_
# 模块训练:
特征变换:
- 使用公式(hv=σ(Wxv))进行节点特征变换,生成节点嵌入h_v^
- 计算节点特征变换的损失Ltrans(Ltrans=−∑v∈Vyvlog(hv))。
基于强化学习的邻居采样:
- 进入循环,直到满足某个停止条件:
- 计算节点 $ v的相似度得分 S (v, v')和图的相似度度量 G (S)$。
- 使用奖励函数f(p,a)(e) 更新采样概率 $ p$。
- 这个步骤是为了通过强化学习选择最合适的邻居节点进行聚合。
图神经网络(GNN):
对于每一层 $ l$:
- 计算当前层的节点嵌入hv(l)。
生成节点的输出嵌入zv(L),并根据公式(13)计算节点的分类概率 pv(k)
pk(v)公式(13)=Softmax(C[v,k]⋅zv[k])=∑k′Cv,k′exp(zv[k′])Cv,kexp(zv[k])
更新损失:
- 计算 GNN 的交叉熵损失 LGNN
- 计算数据分布矩阵 $ H、散布矩阵 S 和混淆矩阵 R$
- 计算成本矩阵的目标T,并根据公式(20)优化成本损失Lcost
- 最终,结合所有损失,得到 CSGNN 的总损失LCSGNN